
Amazon Personalize 「おすすめ商品」表示機能をためしてみる
Personalizeは、レコメンテーション(recommendation:提案、推薦)の機能です。
イメージでいうと、多くのWebサイトで見かける「おすすめ商品」の表示を実現する機能です。
Personalize を使用すると、Amazon.com が「おすすめ」するのと同じ機械学習テクノロジーを使用して、
Webサイトに「おすすめ商品」表示を用意できます。
Personalize は、カスタム機械学習モデルを採用して、小売、メディア、エンターテインメントなどの
業界全体に高度にカスタマイズされたレコメンデーションを提供することもできます。
Personalize利用者は、Application Programming Interface (API) を介して結果を受け取り、使用した分だけ支払います。
最低料金や前払い料金はありません。
特定のニーズ、好み、ユーザー行動の変化に対応した質の高いレコメンデーションを作成し、
更に履歴データのない新しいユーザーのレコメンデーションなどの難しい問題にも対処できます。
パーソナライズされたレコメンデーションを、数か月ではなく数日で簡単に実装できます。
既存ウェブサイト、アプリケーション、SMS、E メールに統合して、あらゆるチャネルとデバイスに
特別なカスタマーエクスペリエンスを提供できます。
高額なインフラストラクチャまたはリソースのコストは不要で、ユースケースに適したリアルタイム、
またはバッチでのレコメンデーションを柔軟に、または大規模に提供することを可能にします。
Personalizeでのやり取りは、暗号化により保護されます。
コンテンツは、Amazon Key Management Service を介してカスタマーキーと共に暗号化され、ユーザーリージョンに保管されます。
また、管理者はIAMアクセス許可ポリシーを介して Personalize へのアクセスを制御できるので、機密情報は安全かつ極秘に保たれます。
Amazon Personalize の料金
データ取り込み
アップロードされるデータに 1 GB 単位で課金されます。Amazon Personalize にストリーム配信されるリアルタイムデータと、Amazon S3 経由でアップロードされるバッチデータが含まれます。
トレーニング
カスタムモデルをトレーニングするのに費やされる時間に課金されます。
トレーニング時間とは、4v CPU と 8 GiB メモリを使用する 1 時間のコンピューティング能力です。
Personalizeは、最も効率的なインスタンスタイプを自動的に選択し、ジョブを迅速に完了させます。
請求されるトレーニング時間数が、経過時間数よりも長くなる可能性があります。
リアルタイムレコメンデーション
1秒間に作成できるレコメンデーション数をTPS(1秒あたりのトランザクション数)と呼びますが、TPSを低く設定すれば時間当たりの料金が低くなり、高く設定すれば料金も高くなります。
設定できる最低設定値は1TPSで、キャンペーンが存在すれば、レコメンデーションがあるかに関わらず、課金されるので注意が必要です。Personalize使わないならばキャンペーン削除がおすすめです。
TPS 時間 = (最小プロビジョンド TPS または実際の TPS のどちらか大きい値) x (5/60 分)
バッチレコメンデーション
バッチ推論ジョブでは、USER_PERSONALIZATION レシピと PERSONALIED_RANKING レシピの使用時には処理されたユーザー数に対して料金が発生し、
RELATED_ITEMS レシピ使用時には処理されたアイテム数に対して料金が発生します。
(参考)TPSを最低値の1TPSに指定しても、1時間あたり0.20ドル、1日あたり0.20×24=4.8ドル、
1か月あたり4.8×30=144ドル(1万5千円強)かかります。
無料枠:サインアップ後、最初の 2 ヶ月間
・データ処理およびストレージ 毎月最大 20GB
・トレーニング 毎月最大 100 トレーニング時間
・レコメンデーション 最大 50 TPS 時間のリアルタイムリコメンデーション/月
Amazon Personalize ハンズオン
アマゾンが用意している初心者向けシナリオに沿って、Personalizeを試しました。
1.データの準備
シナリオで用意されているデータを用意します。
9700本の映画に対する 600人のユーザーの評価履歴に基づいて、映画のリコメンデーションを行います。
学習データとなる評価履歴のデータをダウンロードして、解凍します。
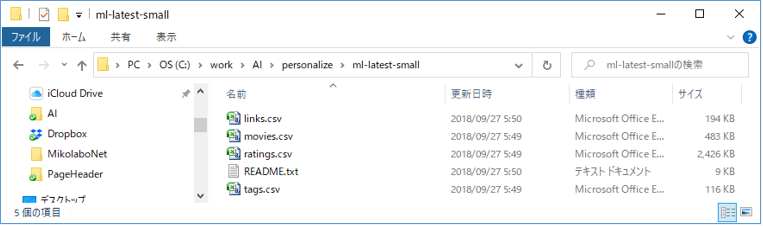
ダウンロードした zip ファイルを解凍し、その中の ratings.csv を使用する
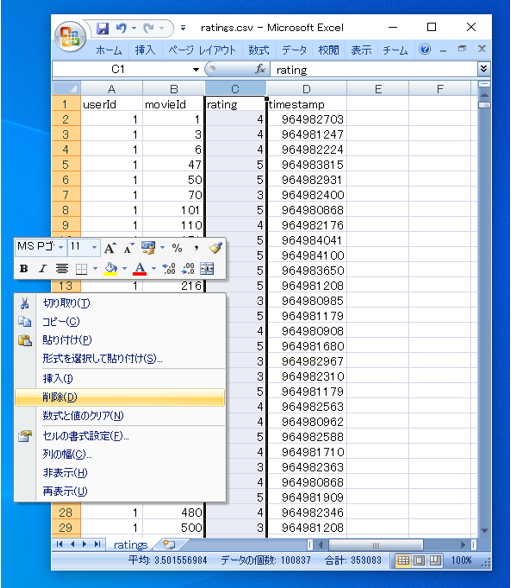
ratings の列を削除する(EXCELで編集した)

ヘッダを Personalize にあわせて、
「USER_ID」「,ITEM_ID」「TIMESTAMP」に変更する
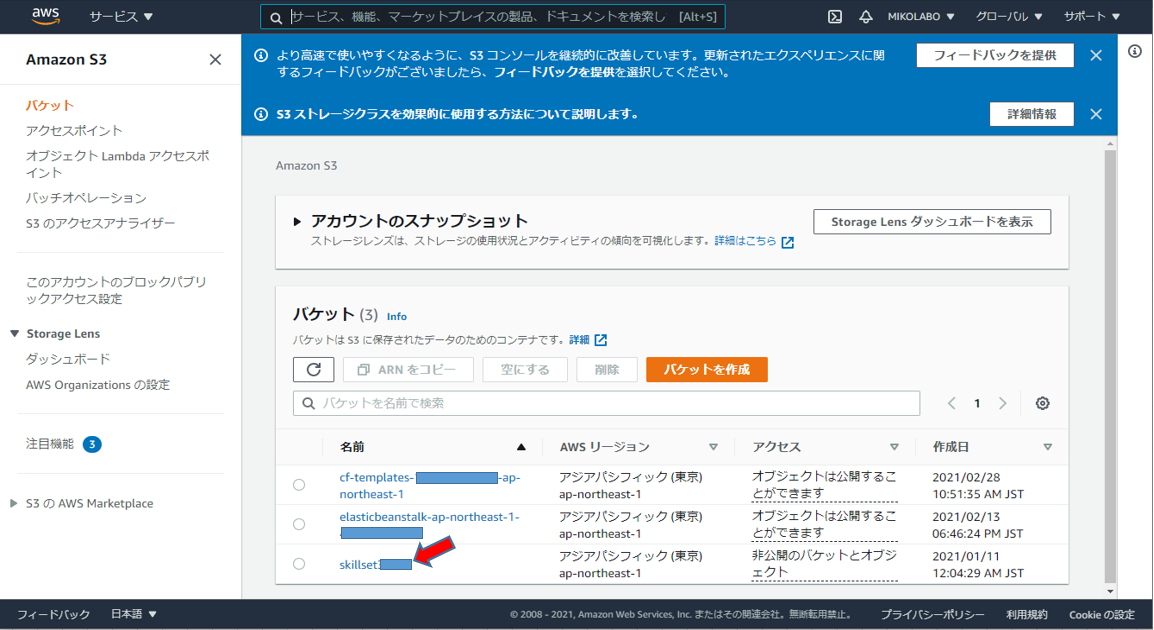
マネジメントコンソールからS3画面を表示し、CSVファイルをアップロードするバケットを選択
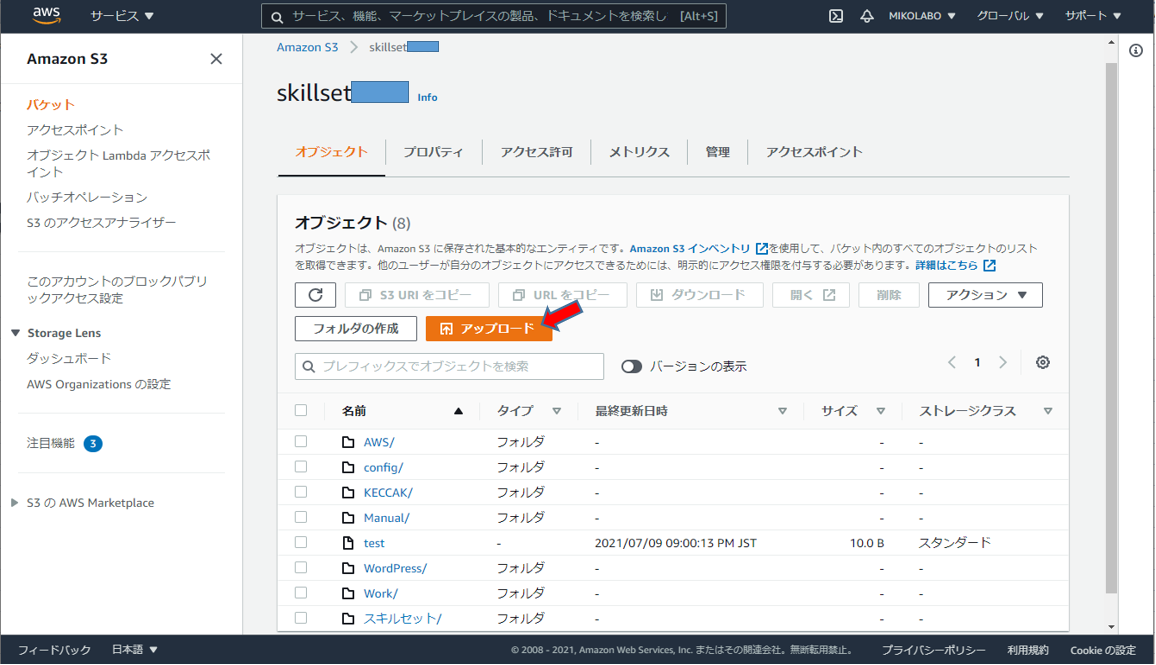
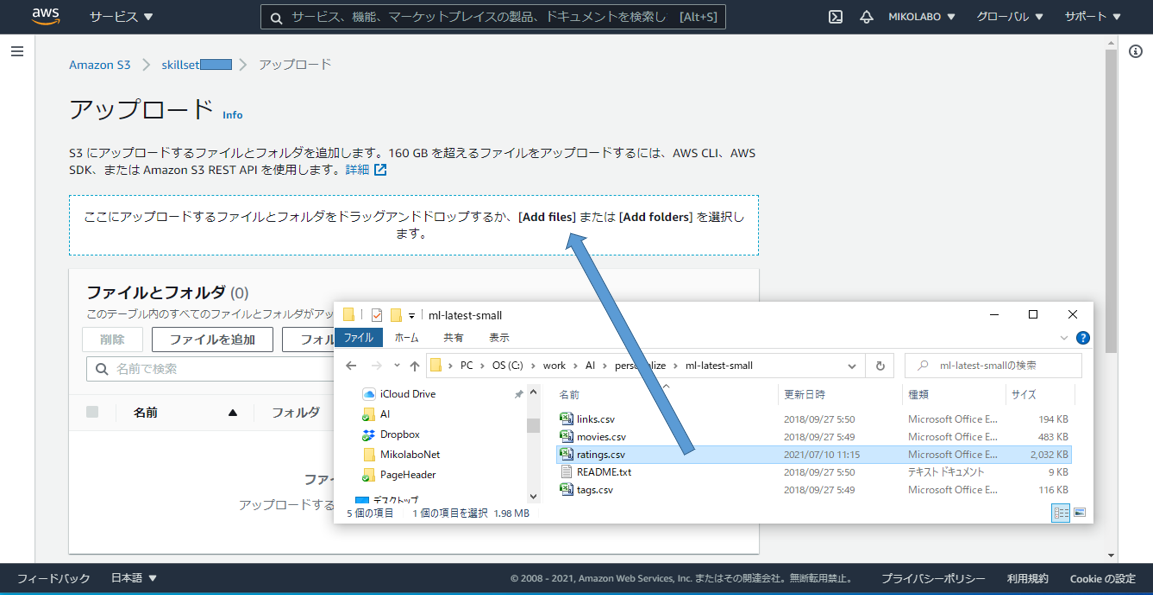
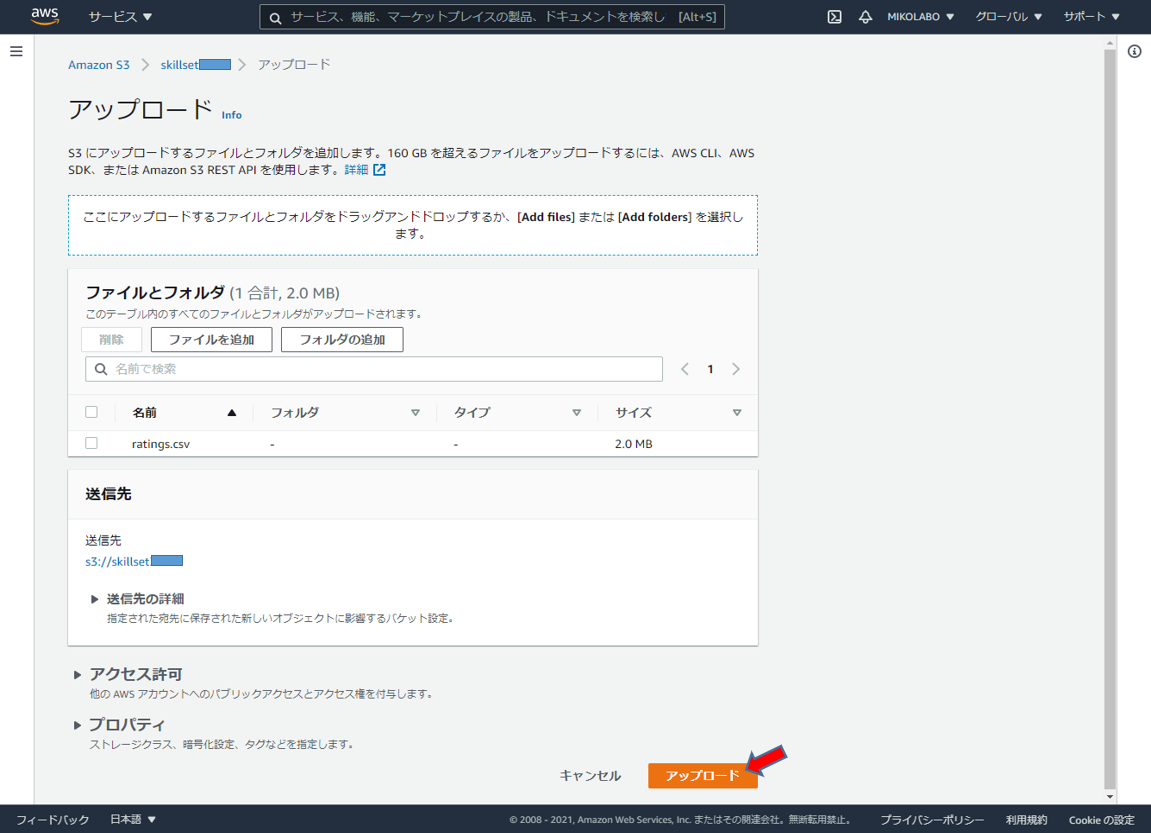
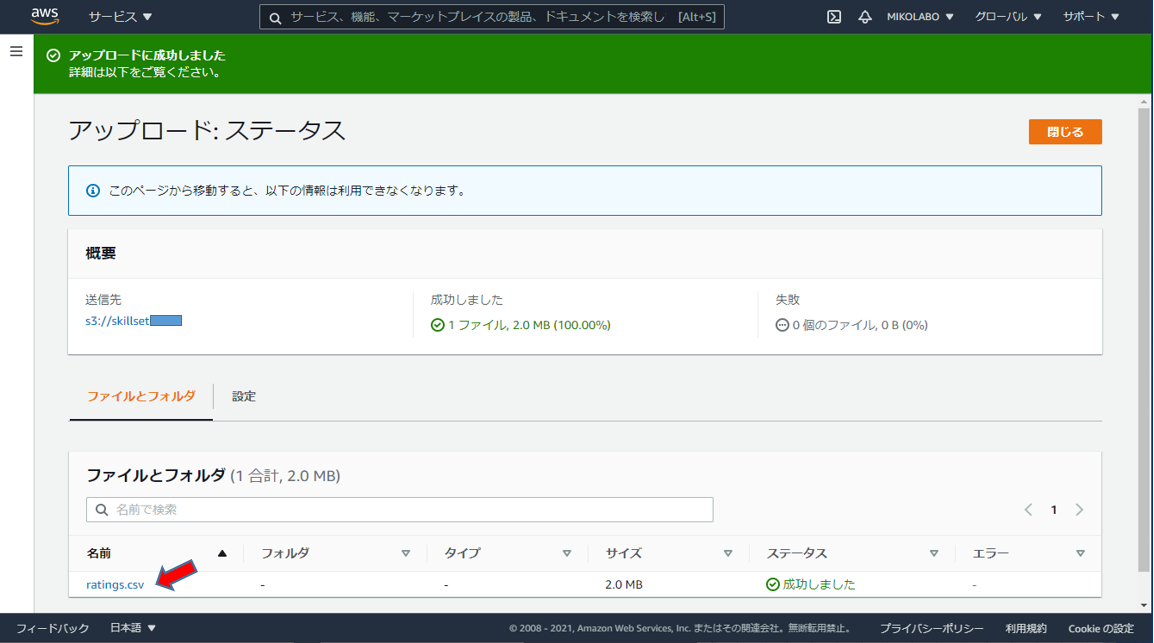
CSVファイルがアップロードされました。
アップロードしたCSVファイルをクリック
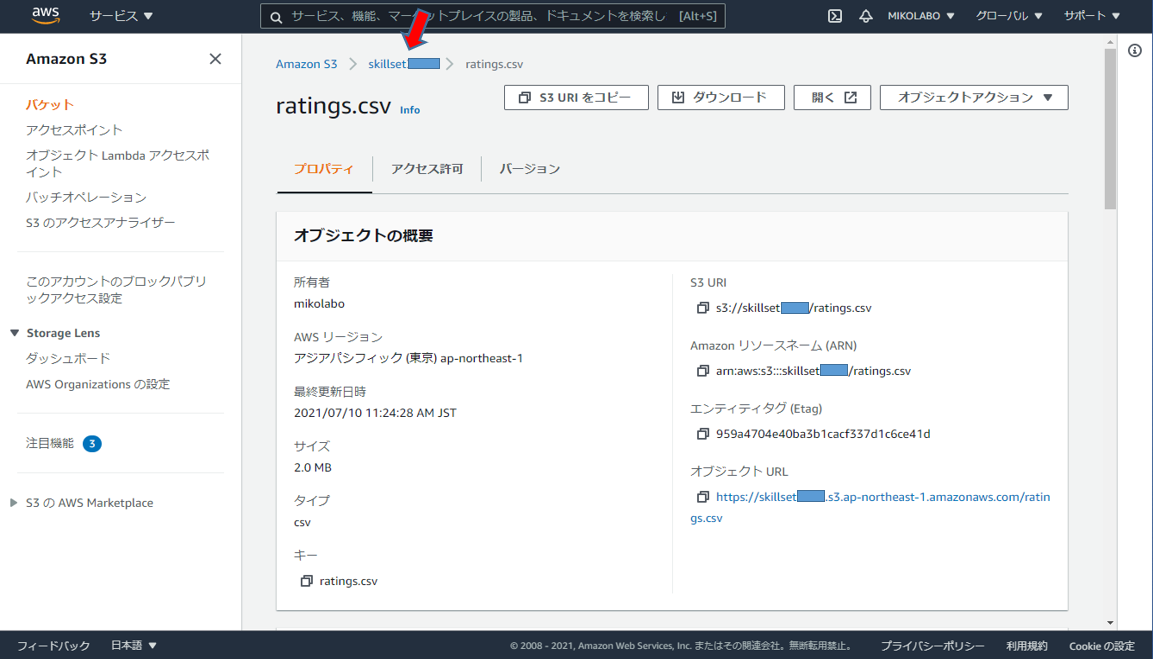
「S3 URI をコピー」をクリックして、URLをメモっておく
s3://skillsetxxxx/ratings.csv
再度、バケットに移動
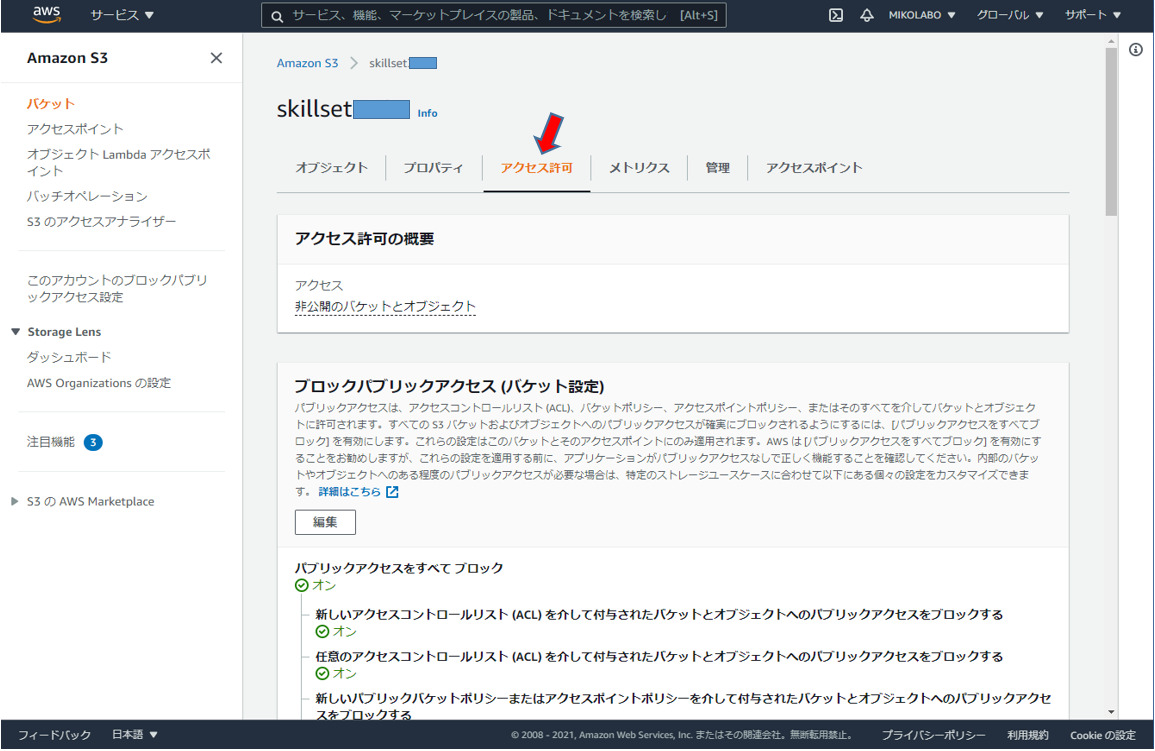
スクロールして、
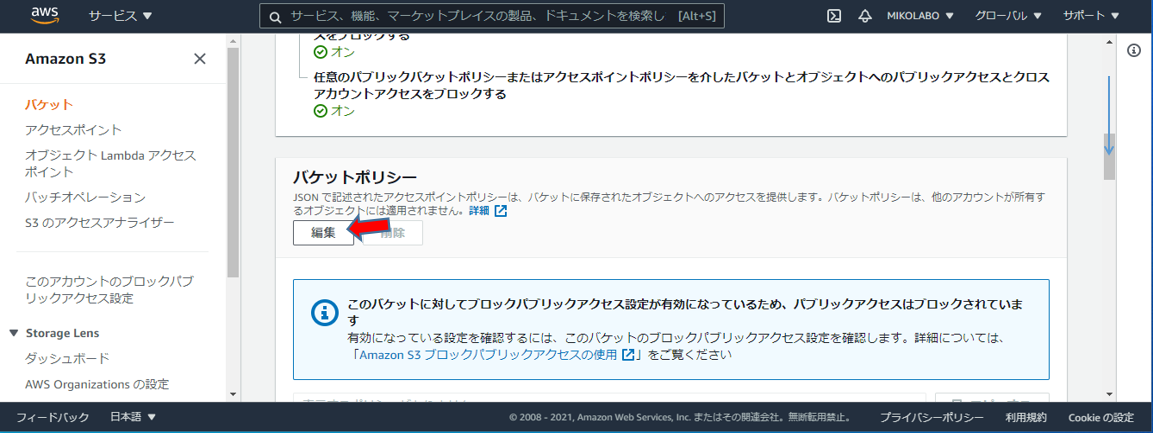
バケットポリシーの
「編集」をクリック
Personalize からバケットアクセスを許可する。
バケットポリシーをコピーして、S3のエディタに貼り付けて保存。(bucket-name を作成したバケット名に変更)
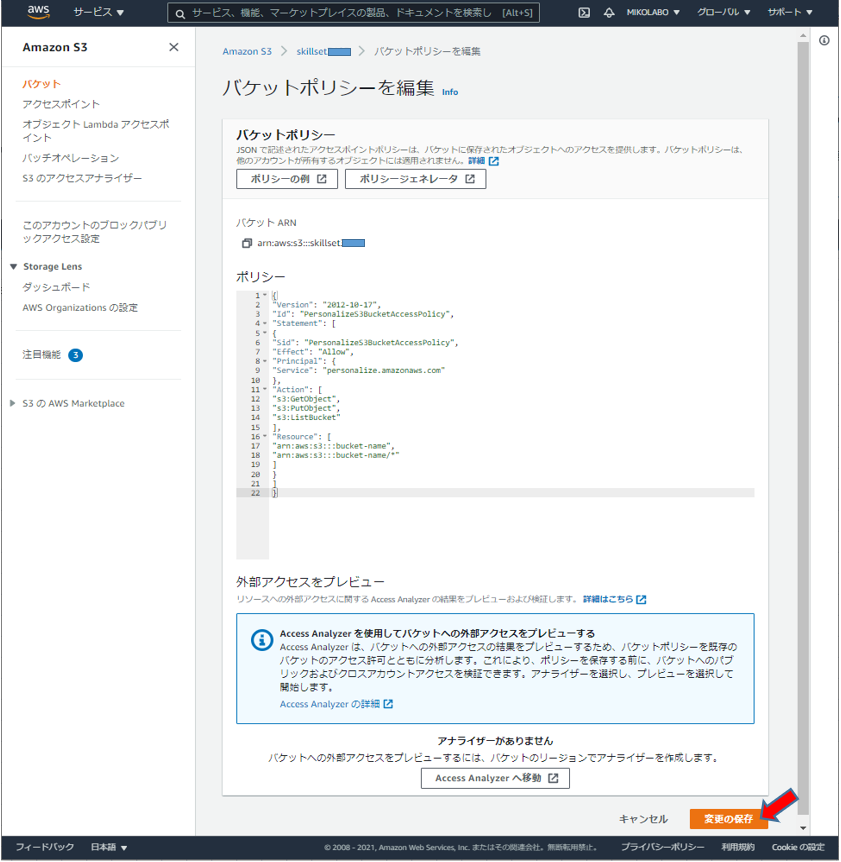
{
Version: “2012-10-17”,
Id: “PersonalizeS3BucketAccessPolicy”,
Statement: [
{
Sid: “PersonalizeS3BucketAccessPolicy”,
Effect: “Allow”,
Principal: {
Service: “personalize.amazonaws.com”
},
Action: [
s3:GetObject,
s3:PutObject,
s3:ListBucket
],
Resource: [
arn:aws:s3:::bucket-name,
arn:aws:s3:::bucket-name/*
]
}
]
}
2. データセットのインポート
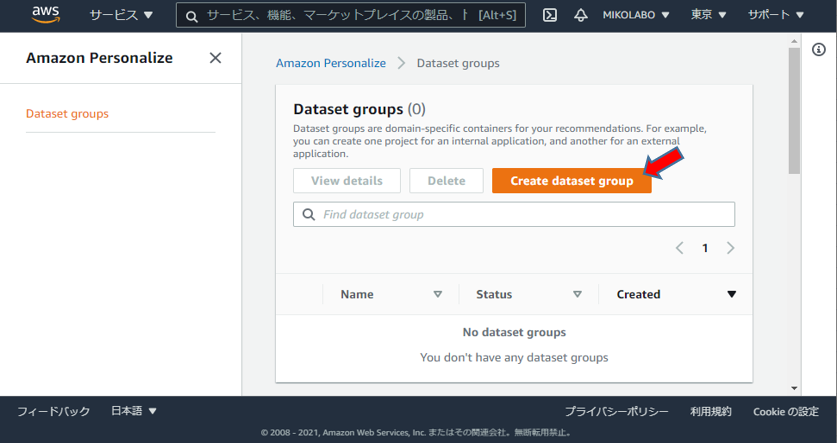
データセットグループを作成
- Create dataset group を選択してデータセットグループを作成
- Interactions (必須), Users (オプション), Items (オプション) の3種のデータセットをデータセットグループに登録可能
- このハンズオンでは、必須の Interactions のみを利用します
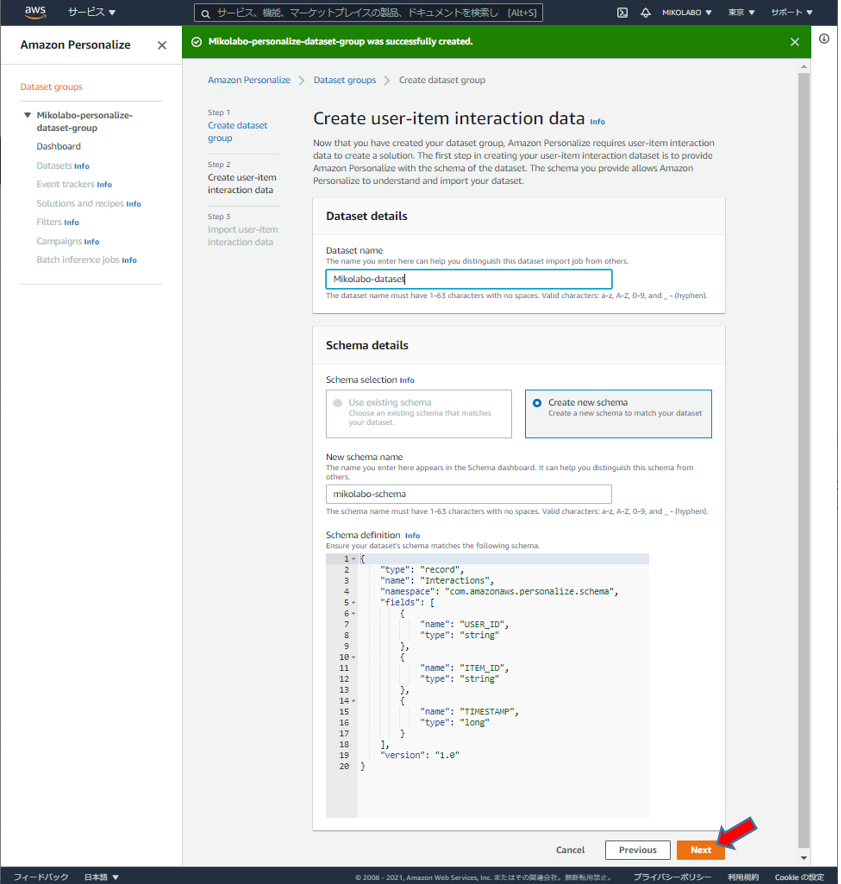
データセットグループの設定
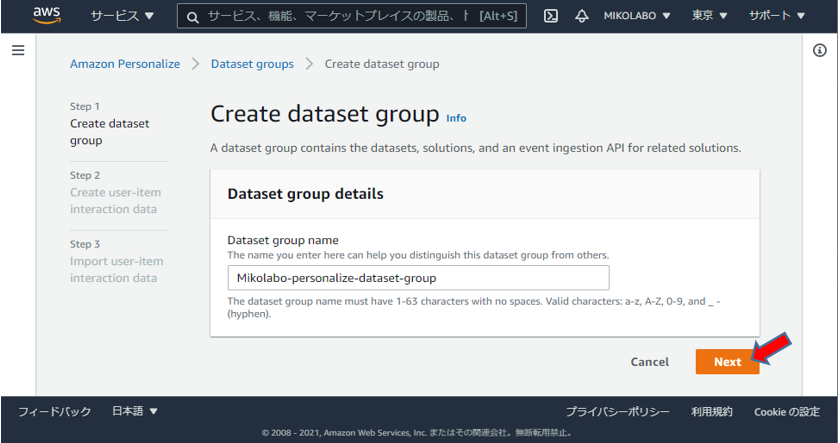
任意の名前を設定
「Next」 をクリック
任意の名前を設定
初めて schema を作るので、
Create a new schema として、
任意の schema name をつける
schema definition はこのまま
(CSV をこれにあわせたので)
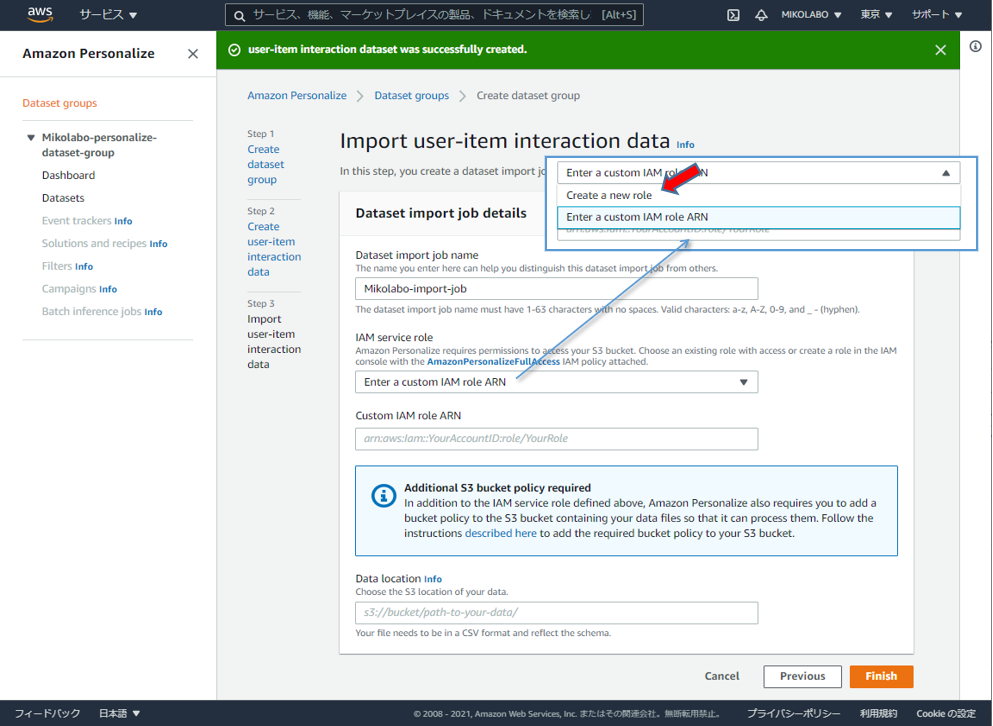
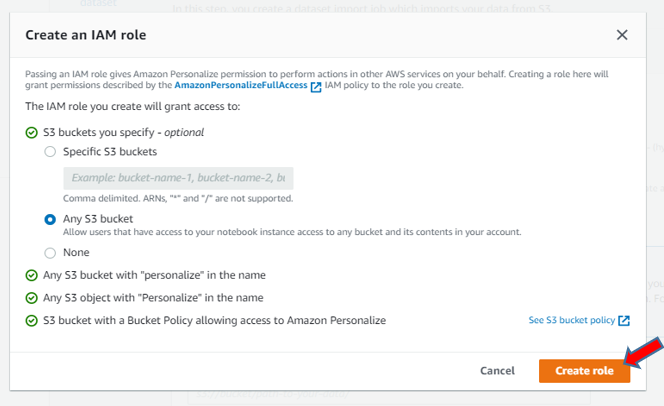
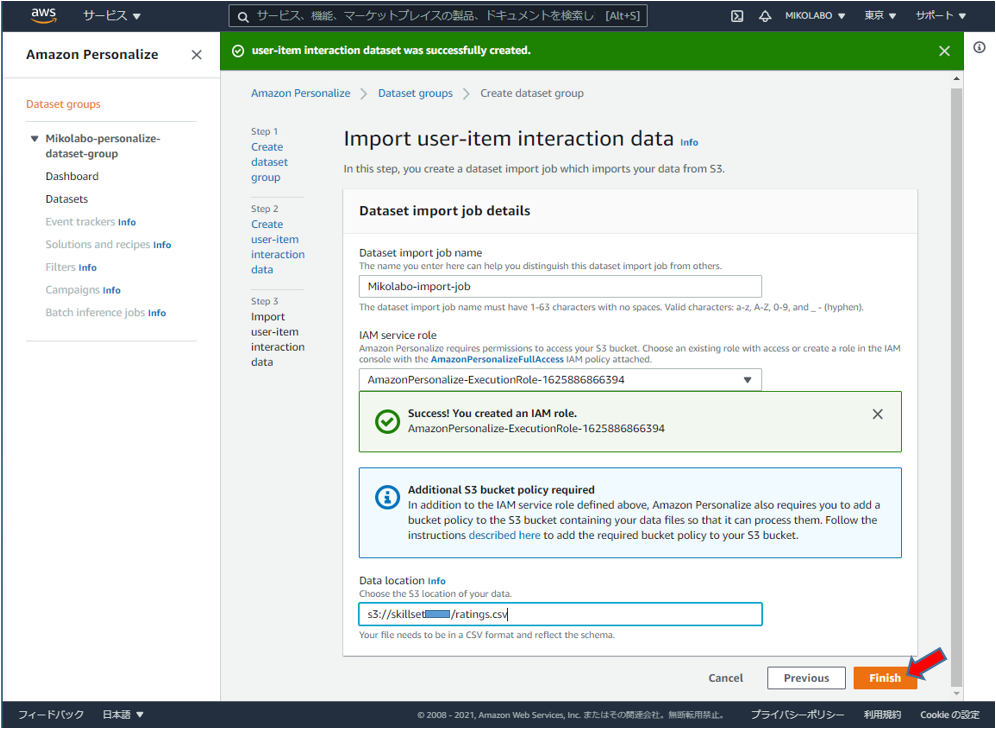
メモしておいたS3 のパスを⼊⼒
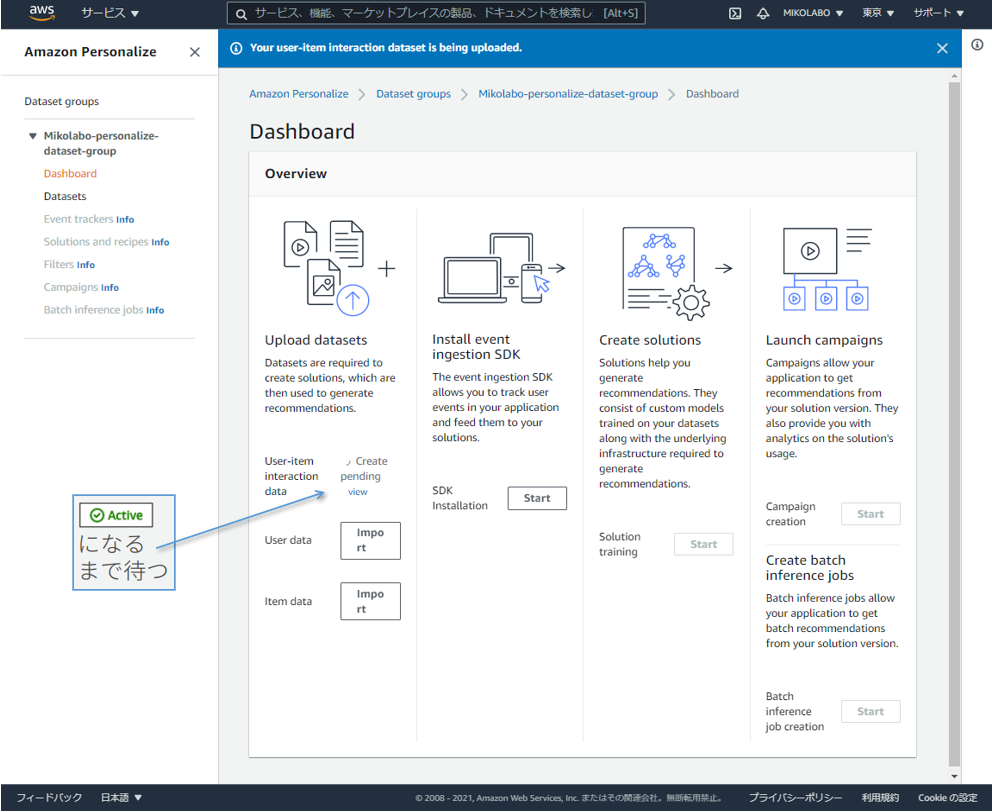
3. ソリューションを学習する
ソリューションの学習画⾯へ移動 データインポートが終わると、ソリューション学習を start できる
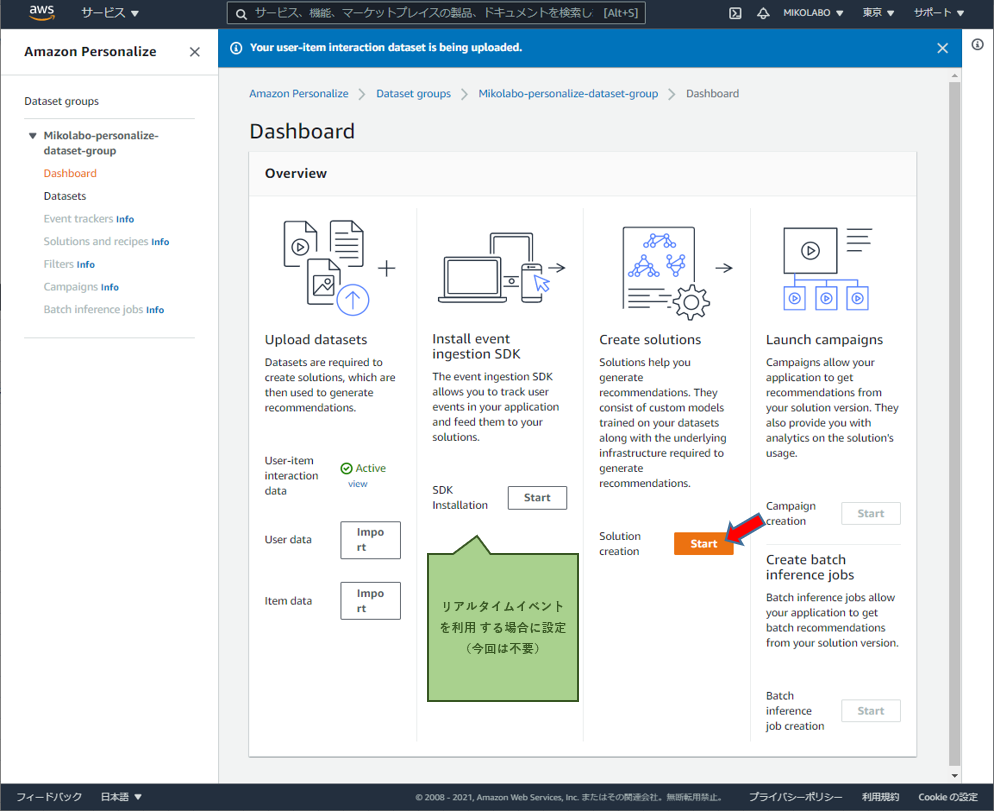
ソリューション学習の設定をする (1/2)
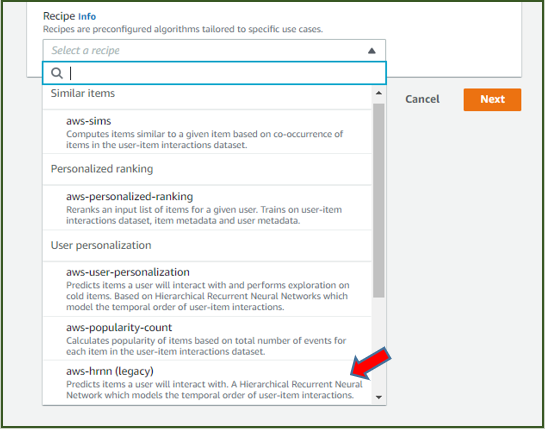
ソリューションの名前設定と学習に利⽤するレシピを選ぶ
学習に利⽤するレシピにaws-hrnn を選択
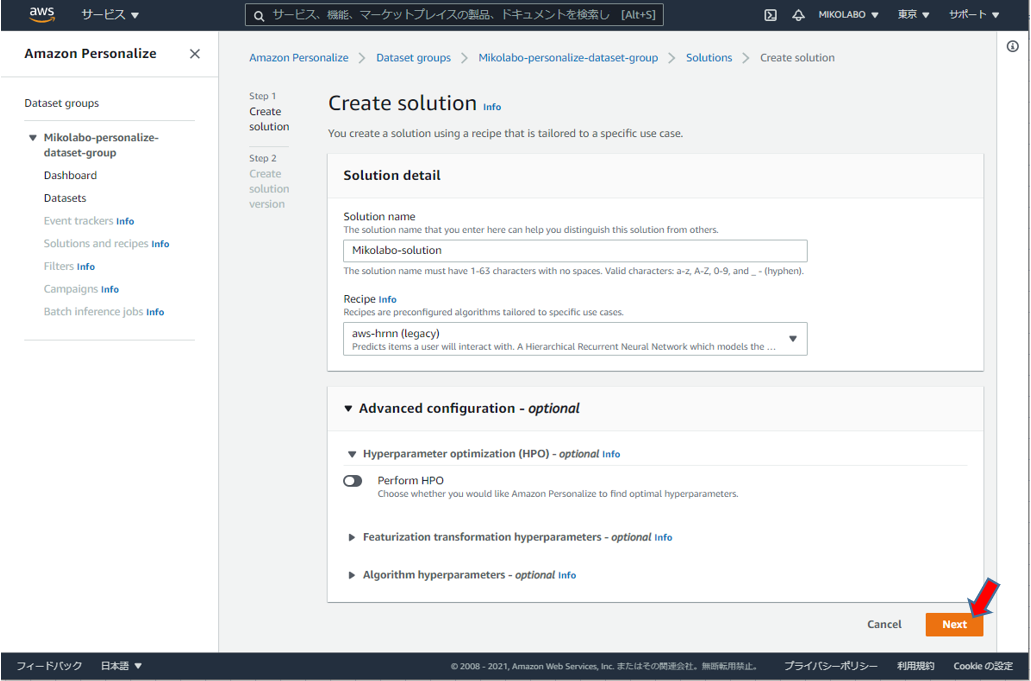
ソリューション学習の設定をする (2/2)
- 履歴の長さによって、学習で考慮するユーザを選択する等の設定を行うう
- デフォルトのまま、画面下のNextを実行
履歴の長すぎる or 短すぎるユーザを除去する
ハイパーパラメータを変更して、アルゴリズムを調整する
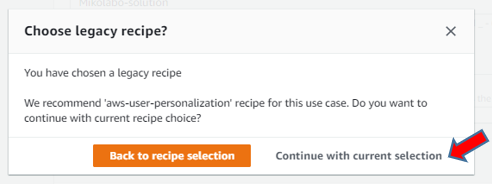
このユースケースには、「aws-user-personalization」レシピをお勧めします。 現在のレシピの選択を続行しますか?
と表示されたが、「Continue with current selection」をクリック
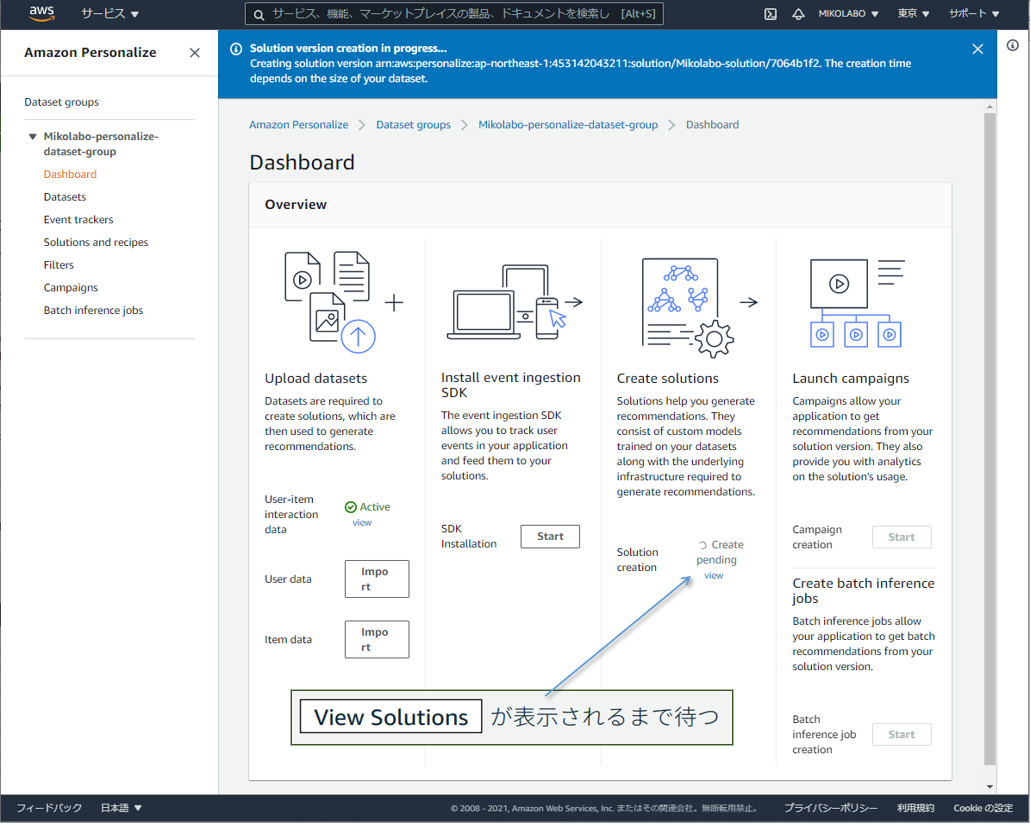
4. キャンペーンを作成して、リコメンデーションを⾏う
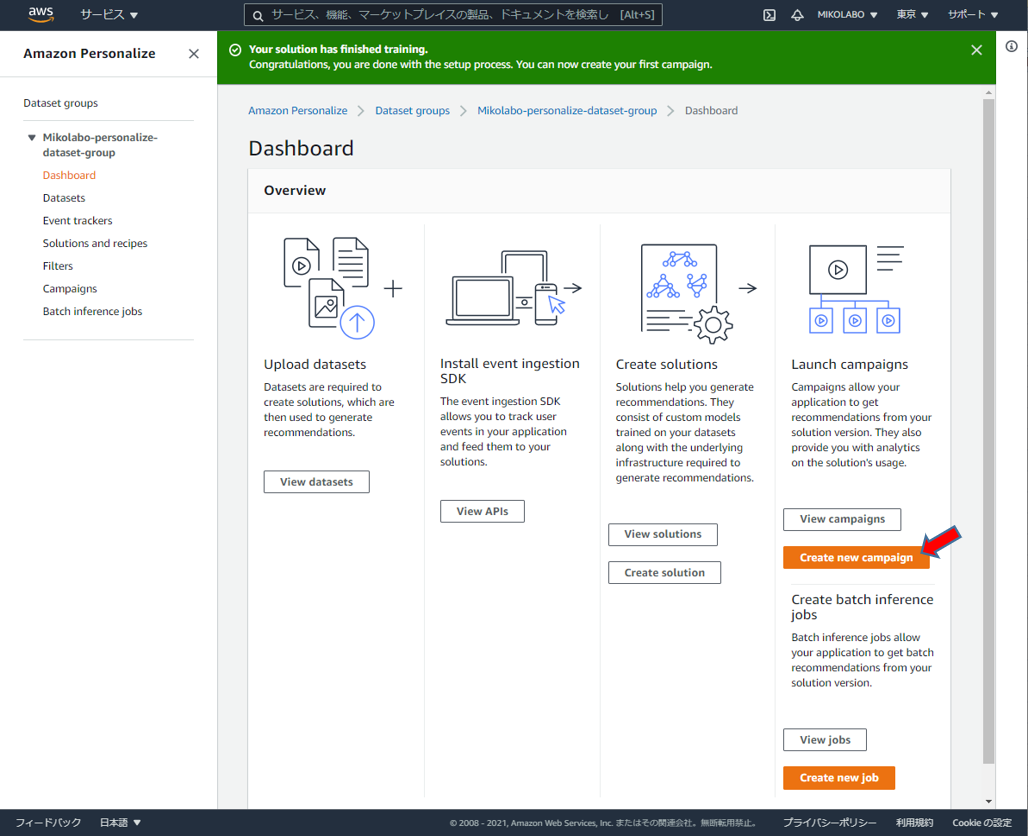
ソリューションの学習が終わるとキャンペーンを作成できる
「View solutions」 が表示され、
「Create new campaign」がクリック可能になる。
「Create new campaign」をクリック
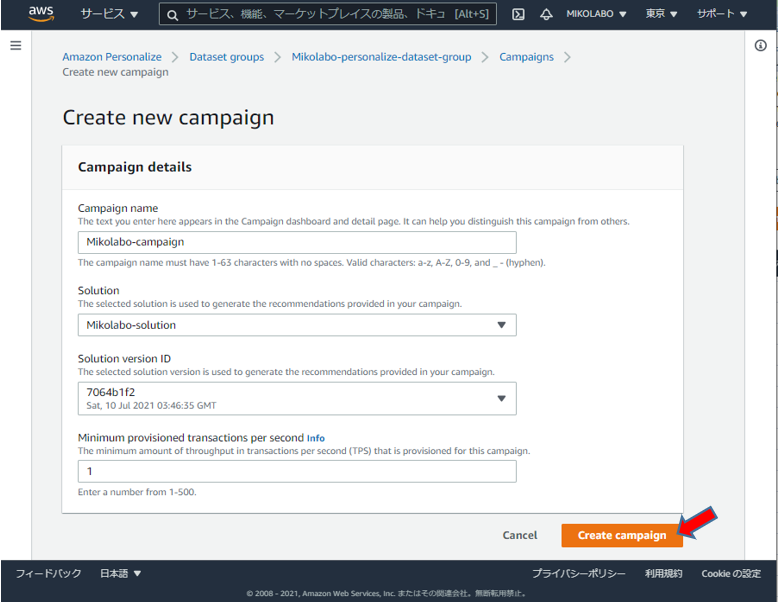
任意の名前を設定
作成したソリューションを選択
ソリューションバージョンを選択(表示そのまま)
1秒間にリアルタイムで応答するリクエスト数(1を入力)
(数に応じた料金がかかる)
「Create campaign」をクリック
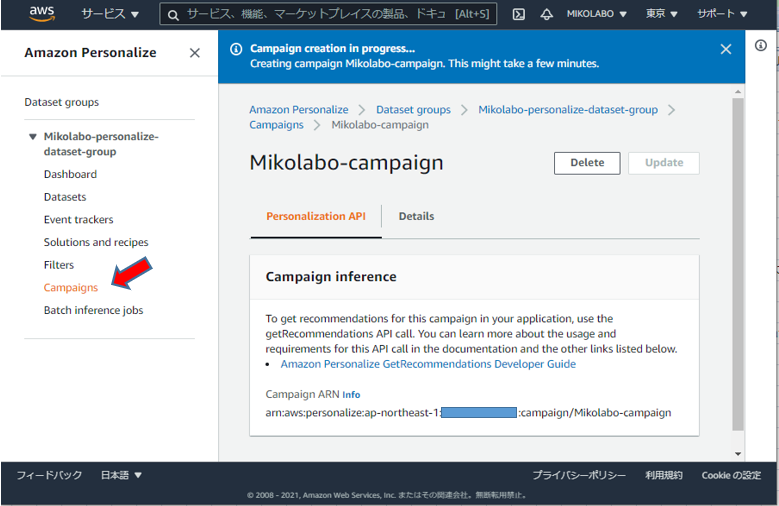
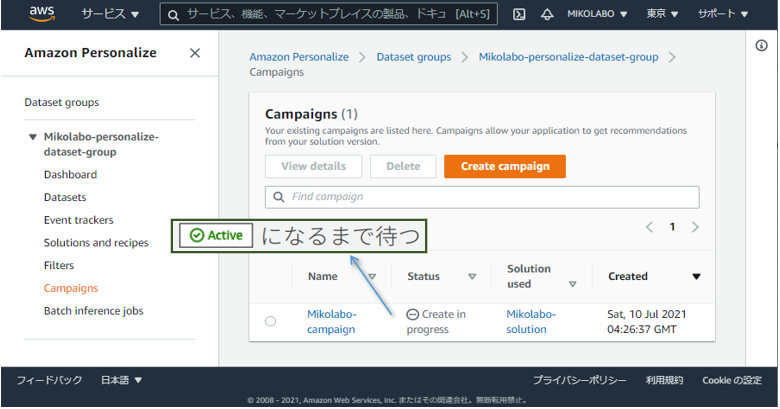
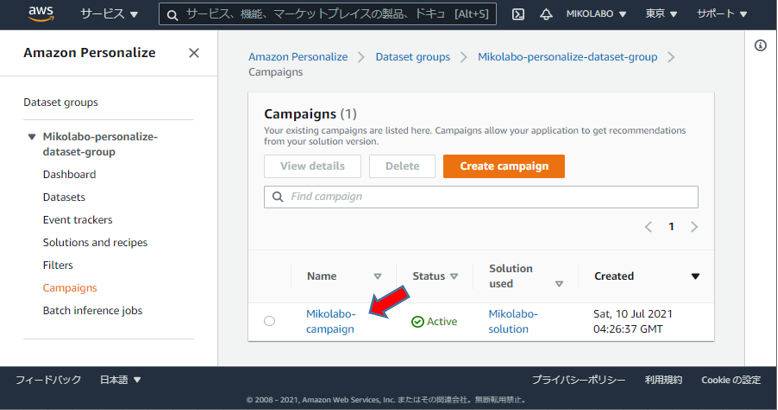
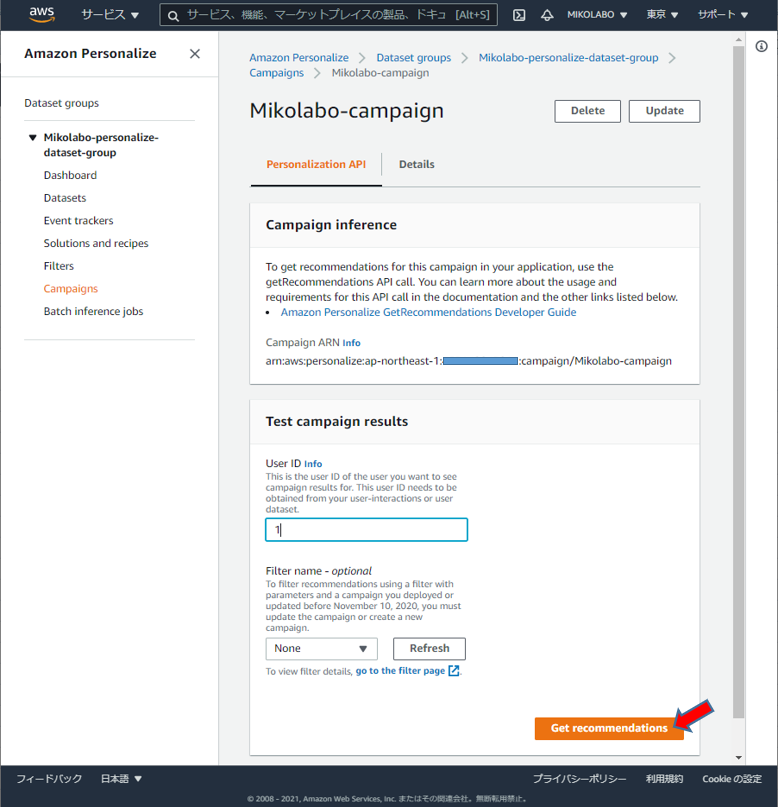
キャンペーンをテストする画⾯が追加されている。
• User ID を⼊⼒ (例えば1)
• Get recommendations を実⾏
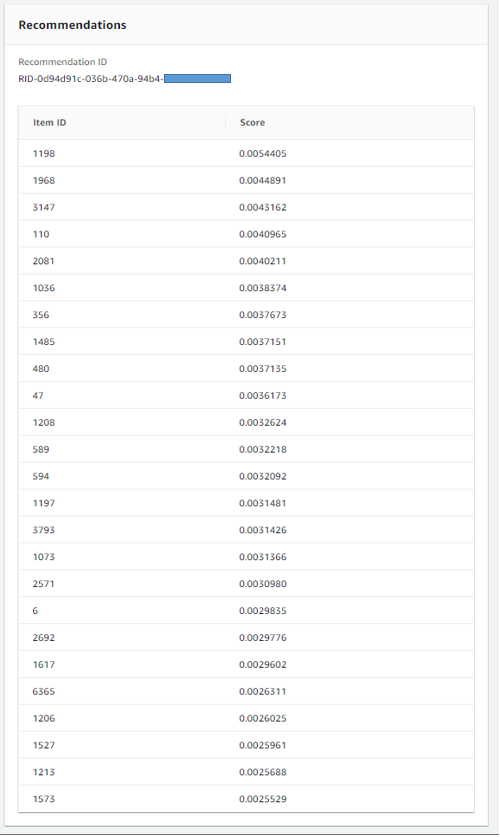
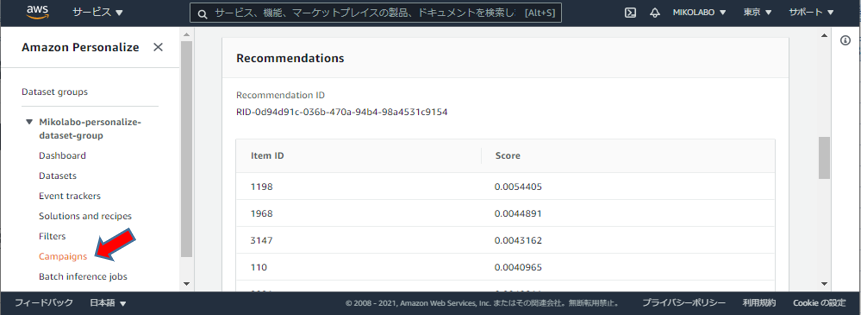
結果の確認
⼊⼒した User ID に推薦すべき Item ID のリストが出⼒される
バッチ推論ジョブの⼊⼒データ準備(Personalize ではなく⼿元のPCでの作業)
- リコメンデーション結果を得たいユーザのリストを json で作成
- テキストエディタで以下のファイルを input.json として保存
{"userId": "1"}
{"userId": "2"}
{"userId": "3"}
{"userId": "4"}
{"userId": "5"}
⼊⼒形式はアルゴリズムによって異なります。
https://docs.aws.amazon.com/personalize/latest/dg/gettingrecommendations.html#recommendations-batch
⼊⼒データをS3にアップロード(S3 での作業です)
- Personalize の画面は開いたまま、S3 にアクセスする https://s3.console.aws.amazon.com/
- Personalize 用に作成したバケットに、input.json をアップロード
- input.json のアップロードを確認・選択し、コピーパスしてメモしておく
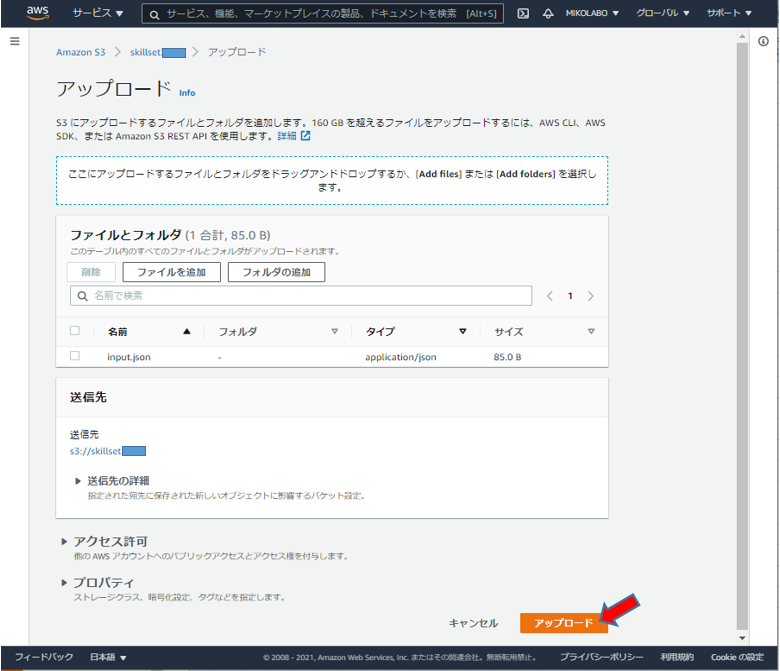
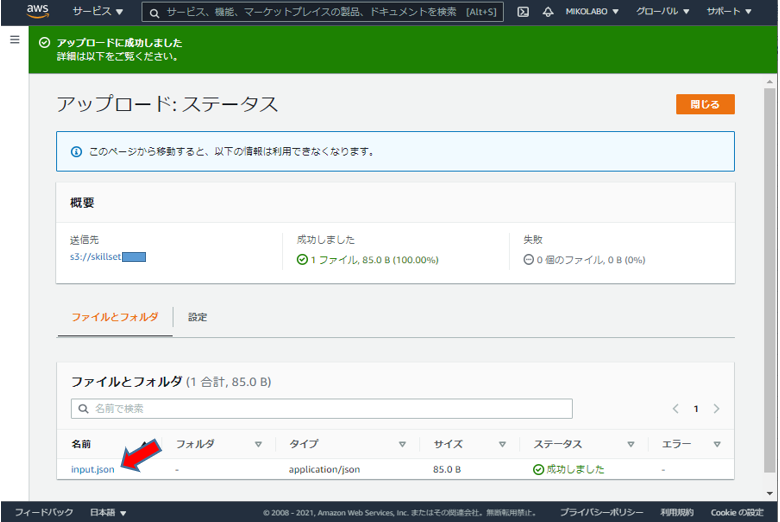
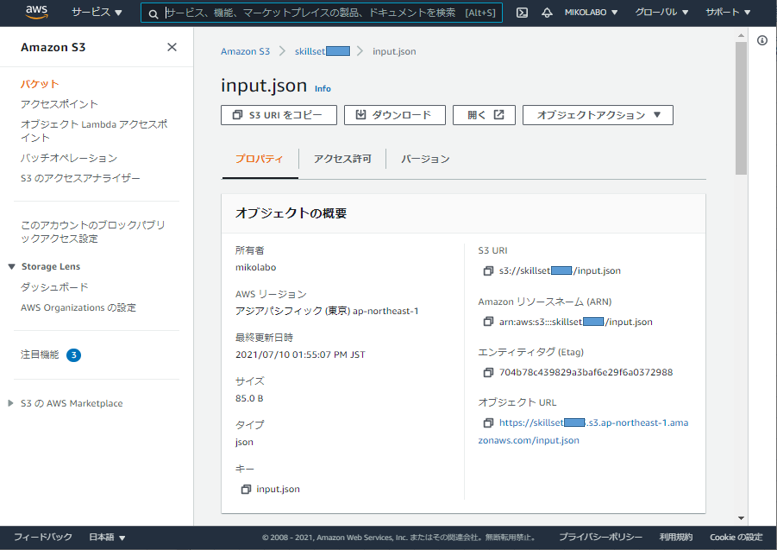
「S3 URI をコピー」をクリックして、メモっておく
s3://skillsetxxxx/input.json
バッチ推論ジョブの設定・実⾏ (1/2)
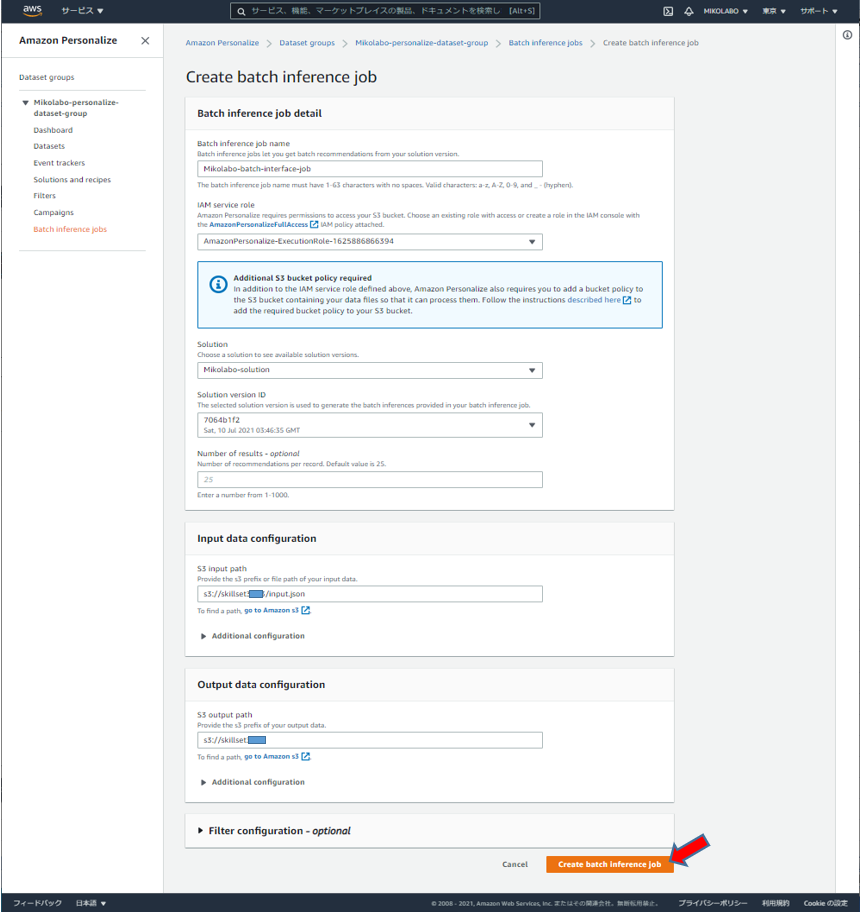
任意の名前を設定
作成したソリューションを選択
ソリューションバージョンを選択
コピーパスした json ファイルのパス
作成したバケットへのパス
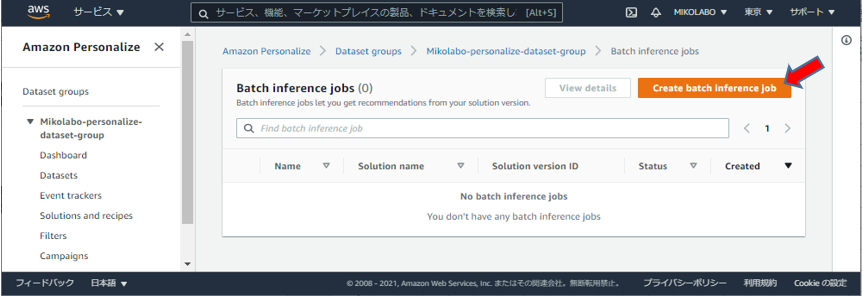
「Create batch inference job」をクリック

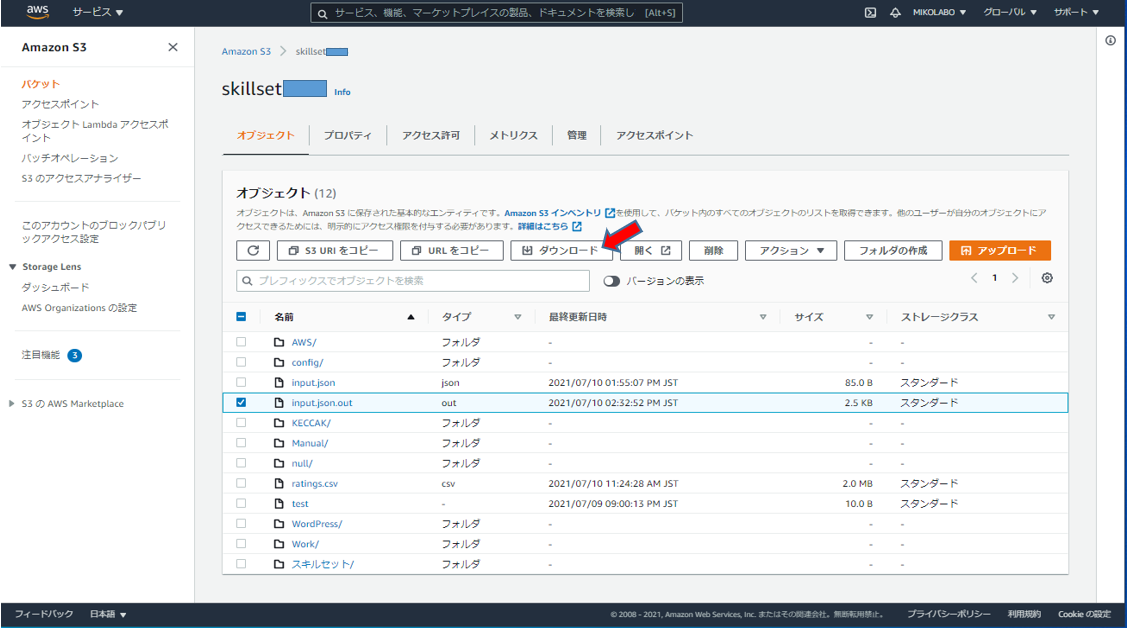
バッチ推論の結果を確認する(S3 での作業です)
- Personalize の画面は開いたまま、S3 にアクセスする https://s3.console.aws.amazon.com/
- Personalize 用のバケットに、出力結果 input.json.out を確認できるので選択
- バッチ推論の結果を確認する


5.リソースを削除する
リソースの削除: S3
- 今回利用したデータ
- エクスポートを実施した場合は、その出力ファイルも削除
リソースの削除: Amazon Personalize
- 左のメニューから、①Campaigns, ②Solutions and recipes, ③Datasets を 順に選び、各ページでDeleteを実行する
- すべて削除すると、左のメニューから ④Dataset groups を選んで、 Dataset groupも削除

