Amazon Forecast で未来の値を予測する
Forecast は、機械学習を使用して精度の高い予測を行うサービスです。
各店舗の在庫数の予測、各会社の財務予測、必要人員数や原材料といった必要リソースの予測など未来を見通せます。
Forecast は、Amazon.com と同じ技術で、機械学習を使って時系列データによって予測を立てますが、使用に機械学習の経験は必要ありません。
Forecast はサーバープロビジョニングも、機械学習モデルの構築、トレーニング、デプロイも不要です。
実際に使用した分のみ料金が発生し、最低料金や前払いの義務はありません。
Forecast は、時系列データと他の変数 (製品の特徴や店舗の所在地など) が相互にどう影響し合っているのかを自動的に判断することにより、予測精度を最大 50% 高めます。
Forecast は予測時間を月単位から時間単位に短縮、設計に何か月も要していた予測精度の水準を、わずか数時間で達成できます。
Forecast では、小売り、物流、金融、広告成果その他を含む、ほぼすべての産業とユースケース向けの予測を立てることができます。
Forecast でのやり取りは、暗号化により保護されます。コンテンツは、Amazon Key Management Service を介してカスタマーキーと共に暗号化され、ユーザーリージョンに保管されます。
また、管理者はIAMアクセス許可ポリシーを介して Forecast へのアクセスを制御できるので、機密情報は安全かつ極秘に保たれます。
Amazon Forecast の料金
予測の生成
例えば、ある店舗商品1個の需要は、10 日間予測であろうが、10 年間予測であろうが、1 つの予測 (1 つの時系列) となります。予測は、1,000 単位 (1,000 未満は切り上げ) で課金されます。
予測はデフォルトで 3 つの分位値 (10%、50%、90%) で生成され、合計予測数は 3 の倍数で増加します。変位値 (1?5)はいつでも上書きし、選択した特定の予測に対してのみ支払うことができます。
データストレージ
Forecastモデルのトレーニングに使用するためのデータ (GB 単位) の保存にかかる料金です。
トレーニング時間
お客様提供データに基づき、カスタマイズ予測モデルをトレーニングする時間に 1 時間単位で課金されます。
特定のシナリオでは、複数ジョブの並行実行や特定リソースを必要とするため、トレーニング時間と実行時間はは必ずしも同じではありません。
時間には予測子と予測の作成に費やされる時間も含まれます。
無料利用枠:最初の 2 か月間は以下無料
予測の生成: 1 か月あたり最大 10,000 の時系列予測
データストレージ: 1 か月あたり最大 10 GB
トレーニング時間: 1 か月あたり最大 10 時間
Amazon Forecast ハンズオン
アマゾンが用意している初心者向けシナリオに沿って、Forecastを試しました。
1.データの準備
過去の家庭の電力使用量のデータから将来の使用量を予測するモデルを構築する
学習データを以下のURLからダウンロード・解凍
(Small) http://bit.ly/22Z4QCj
(Large) https://amzn.to/2kEBwRs
electricityusagedata.csvというファイルを確認する
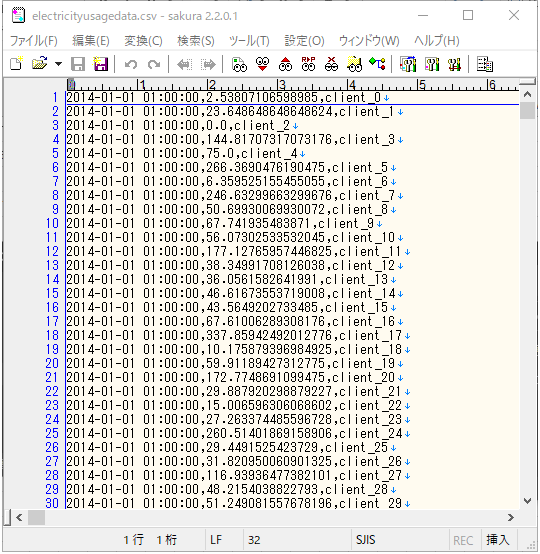
各家庭の毎時の電⼒使⽤量(左から時刻、電⼒量、家庭のID)
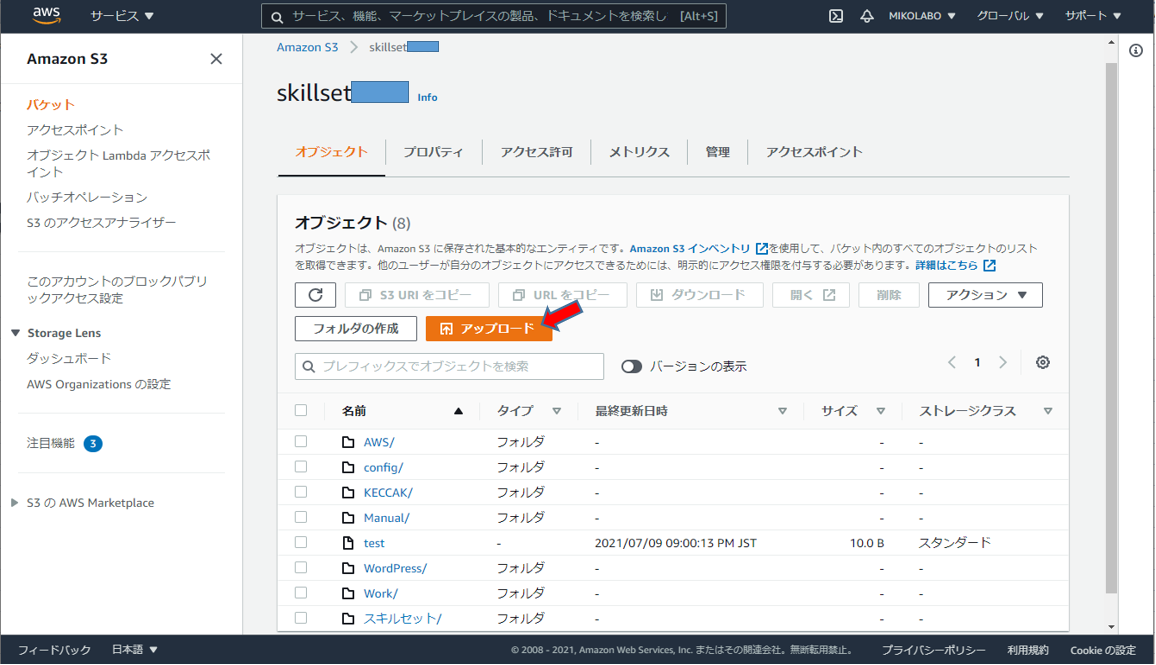

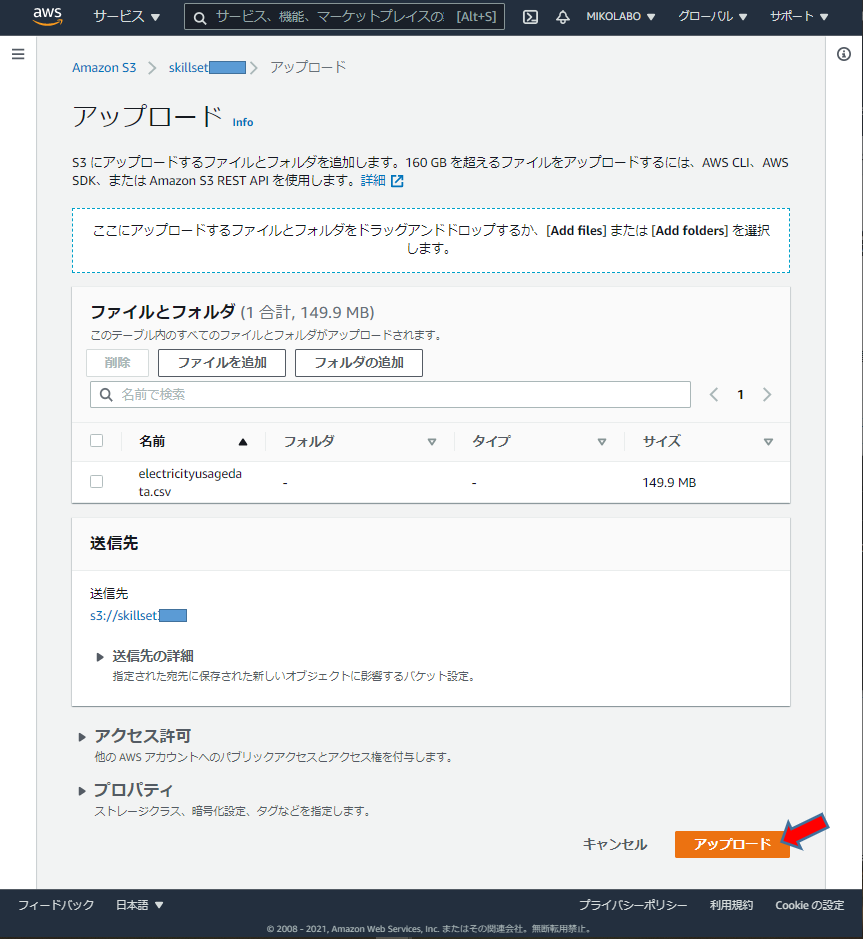

CSVファイルがアップロードされました。
アップロードしたCSVファイルをクリック
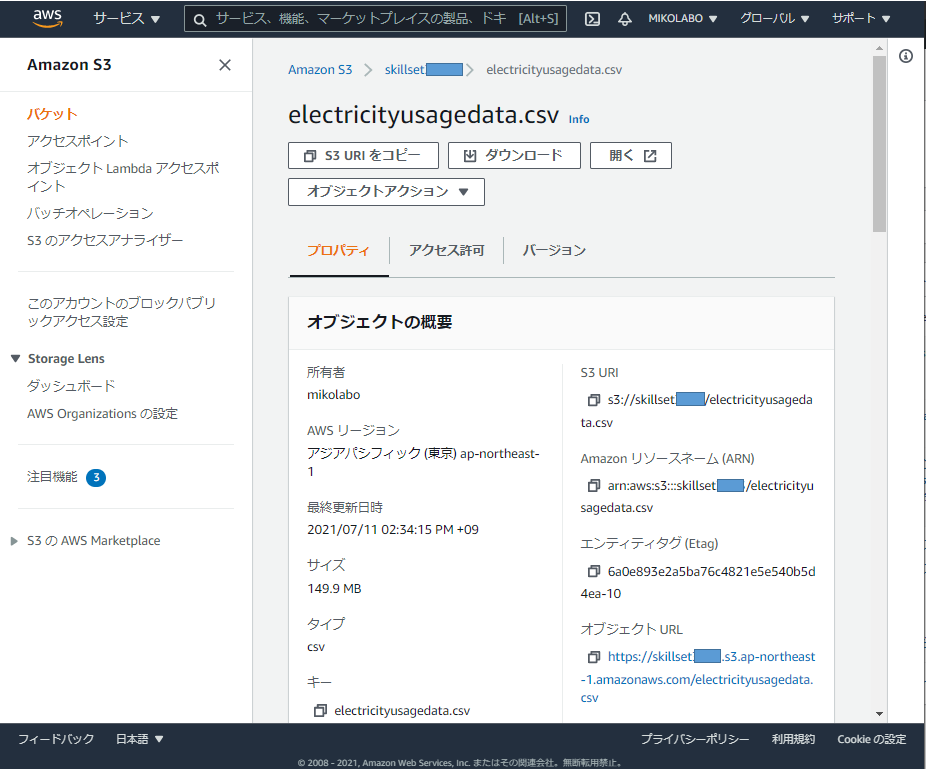
「S3 URI をコピー」をクリックして、URLをメモっておく
s3://skillsetxxxx/electricityusagedata.csv
2. データセットのインポート
左の Ξ からメニューを 開き、「Dataset groups」メニューが表⽰されるのでクリック
データセットグループを作成
- Create dataset group を選択してデータセットグループを作成
- TARGET_TIME_SERIES, RELATED_TIME_SERIES, ITEM_METADATA の3種のデータセットを
データセットグループに登録可能 - このハンズオンでは、必須の TARGET_TIME_SERIES のみ利用する
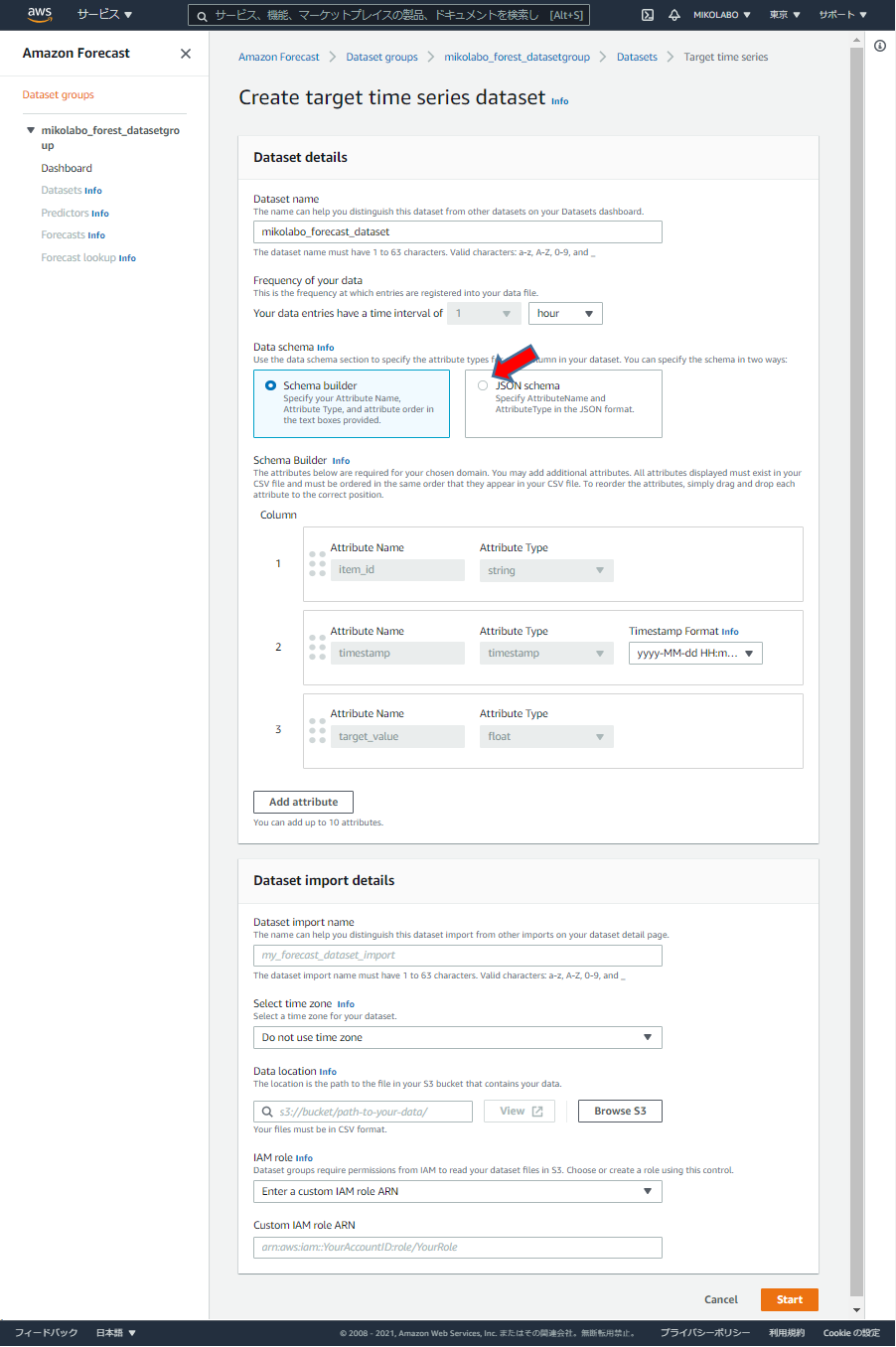
データセットグループの設定

任意の名前を設定
※ Personalizeは大文字英字OKだったが、
Forecastはダメ見たい
Custom を選択
タグも一応設定した
「Next」 をクリック
hour を選択
CSV ファイルの列順に並び替えるため、
「JSON schema」をクリックする
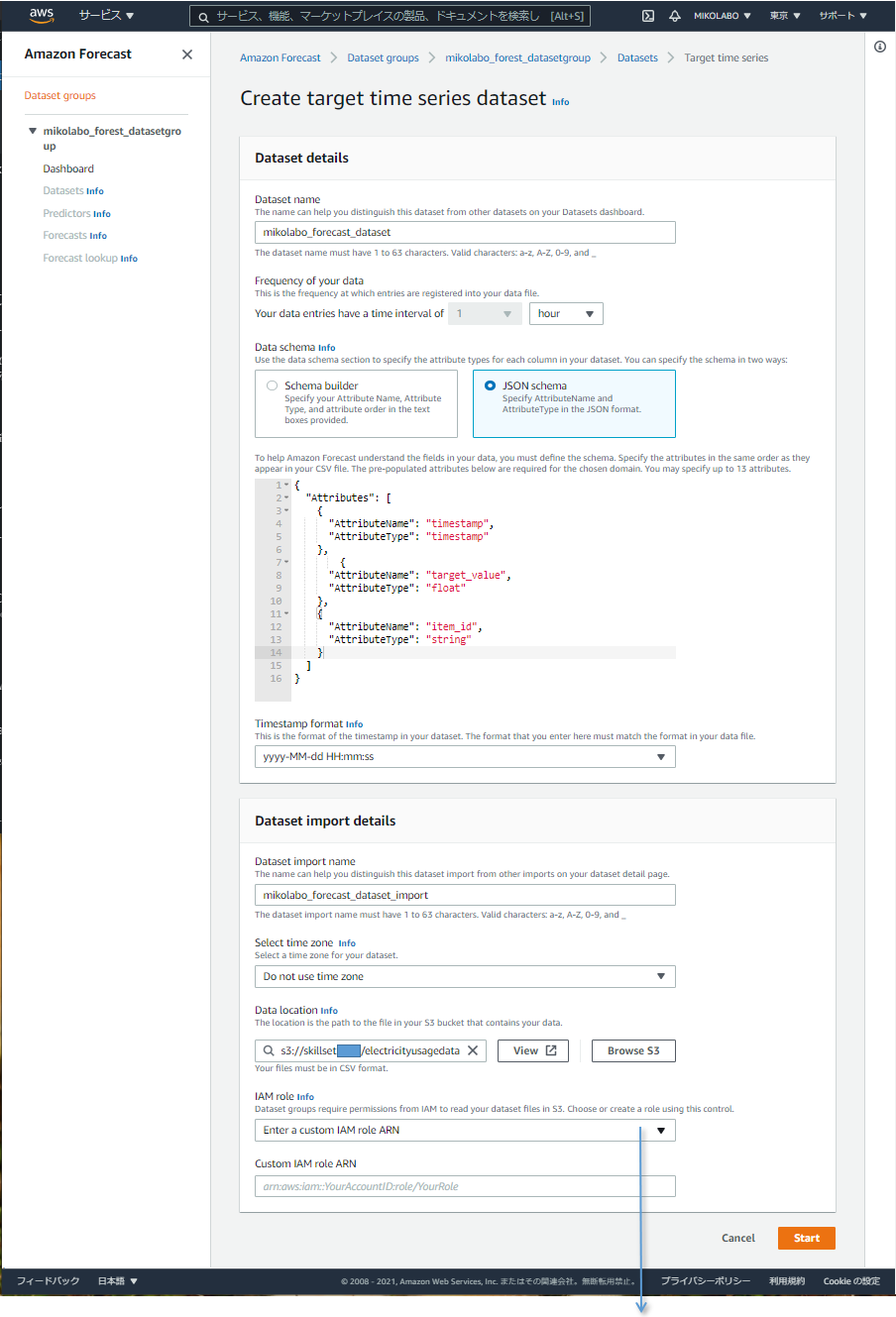
データに合わせて、定義を直して、並び順を変えた。
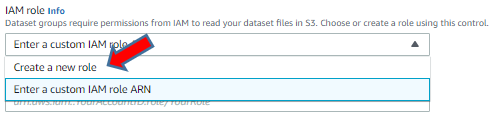
create a new role 選択
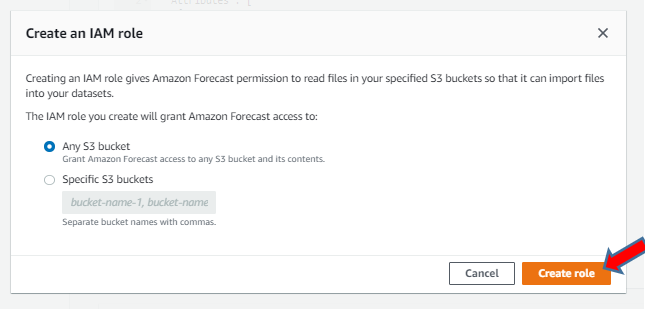
Any S3 bucket を設定する
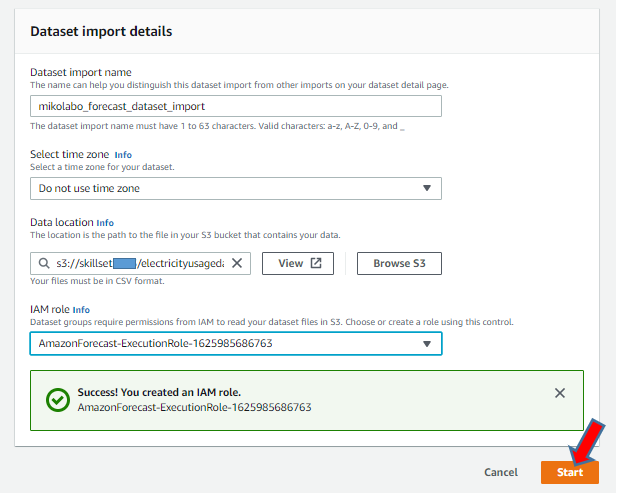
任意の名前を設定
メモしておいたS3 のパスを入力
作成した Role が設定される
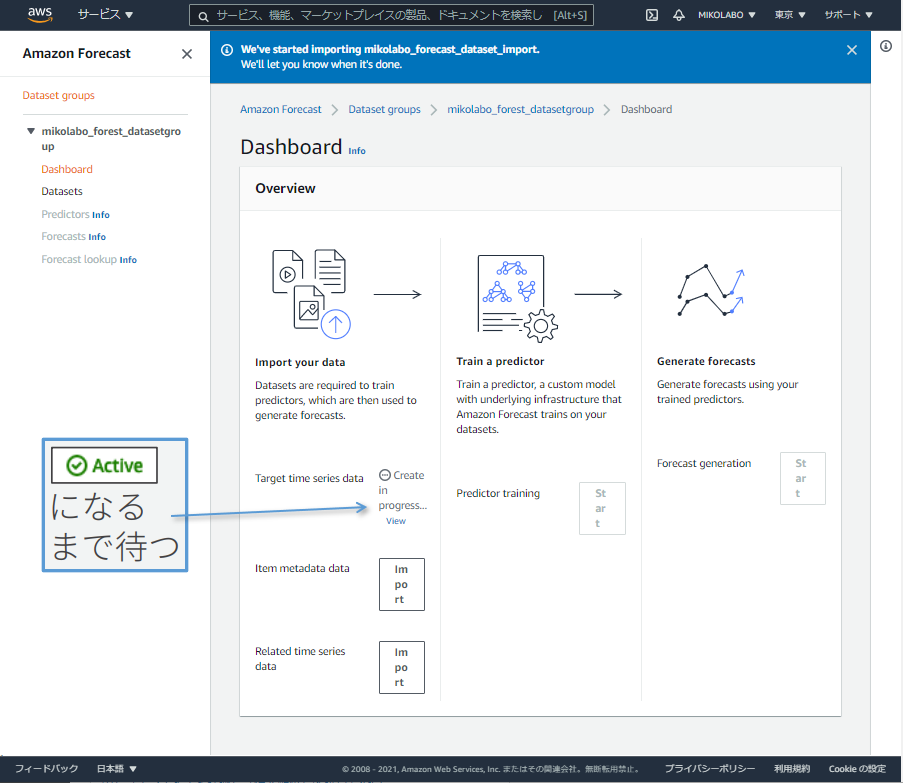
3. Predictor を学習する
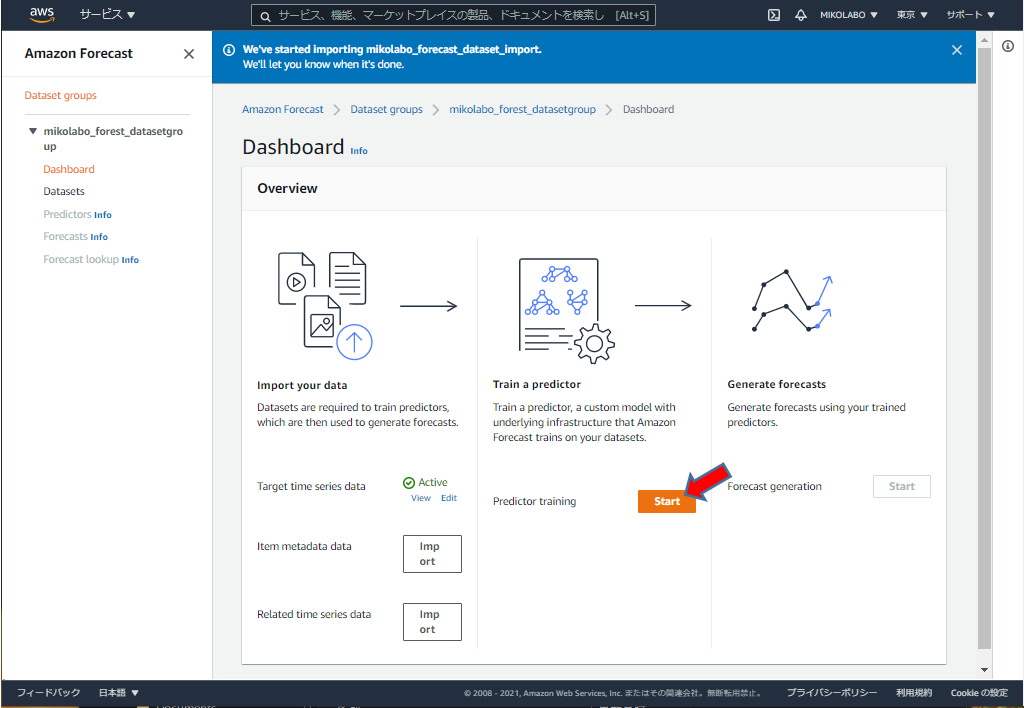
データインポートが終わると、Predictor の学習を start できるようになる
「start」をクリック
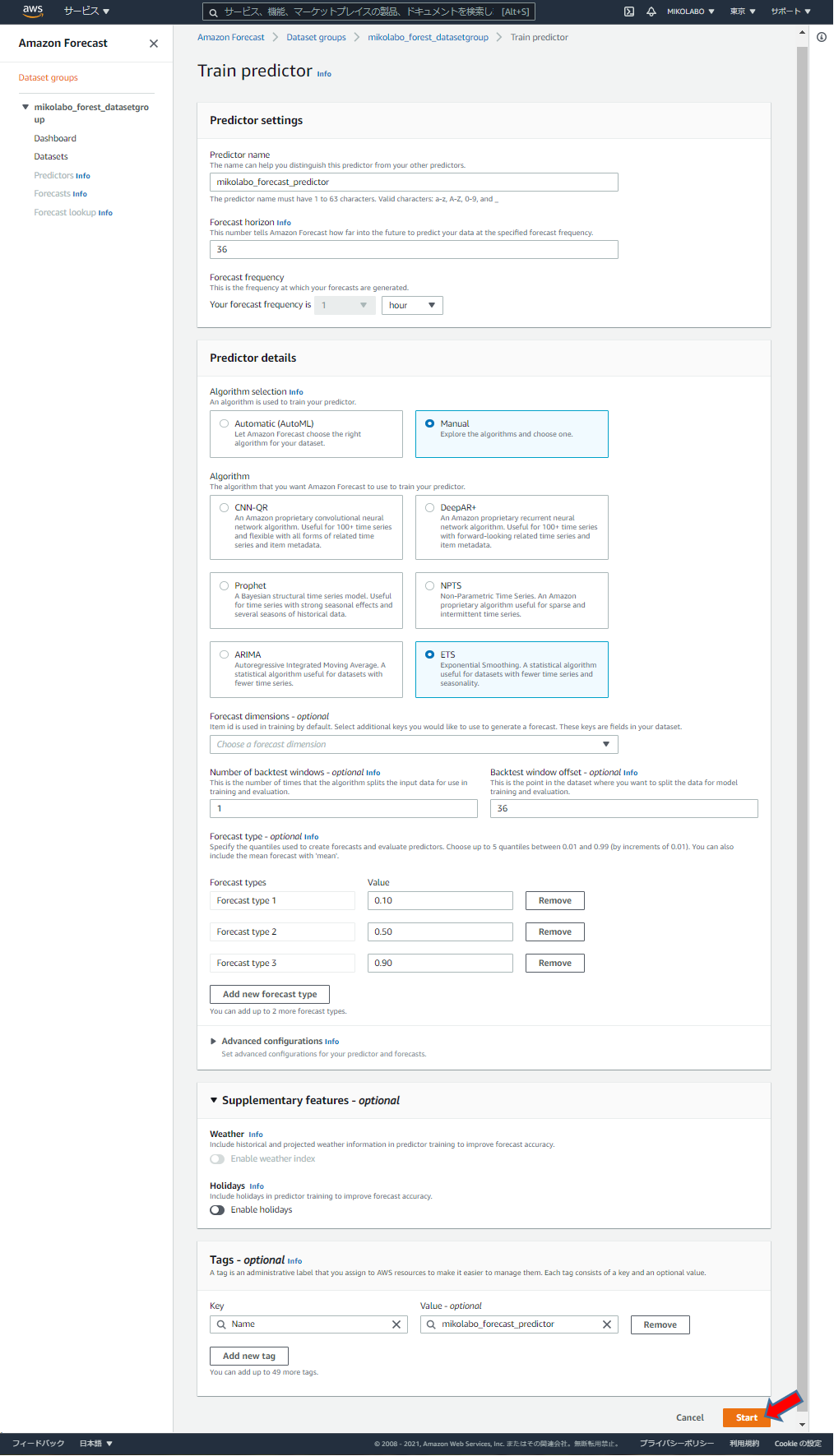
任意の名前を入れる
予測したい期間を入れる
(36といれると 36 時間先まで予測)
hour を選択 (予測期間の単位)
Manual を選択し、任意のアルゴリズムを選択
今回はETSを選択
タグも一応設定した
「Start」をクリック
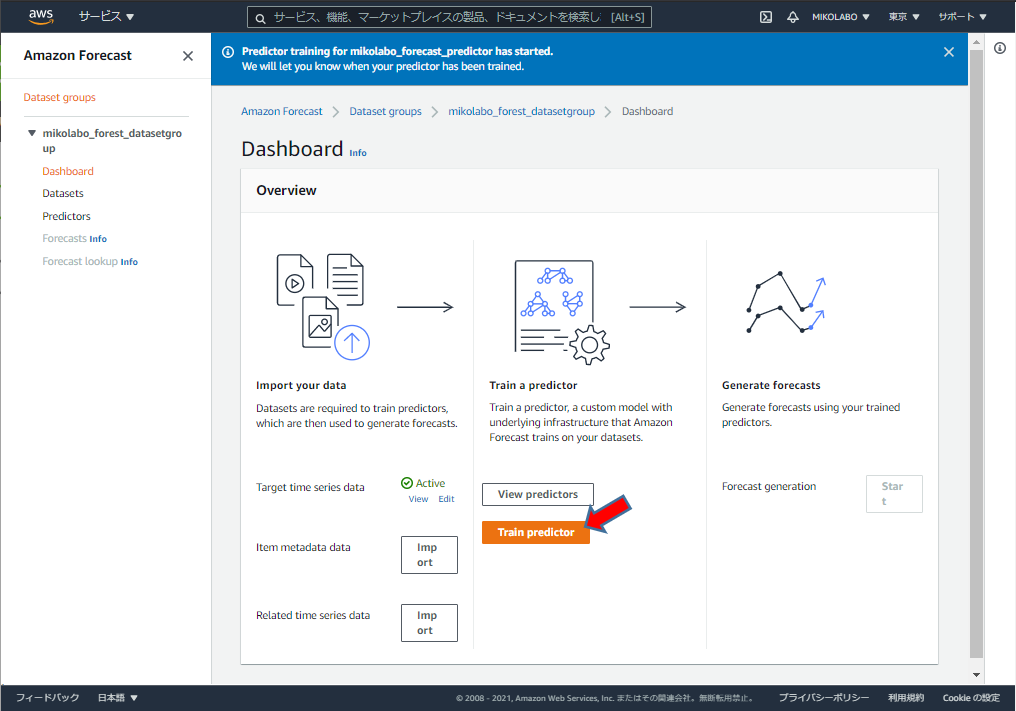
「Train predictor」をクリック
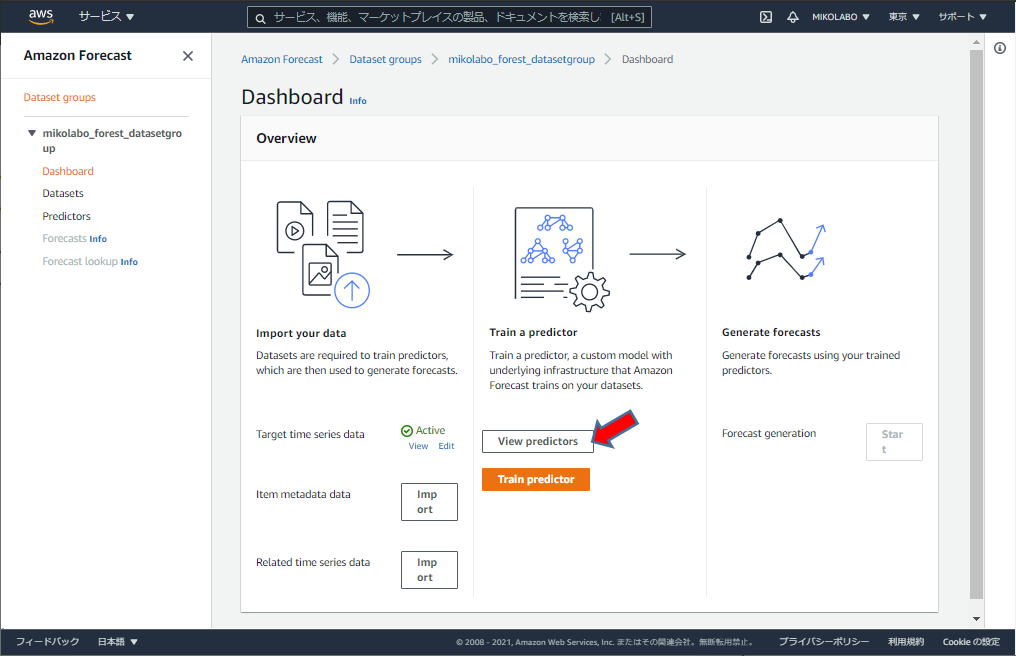
学習完了まで待つ。進捗を確認するために、
「View predictors」をクリック
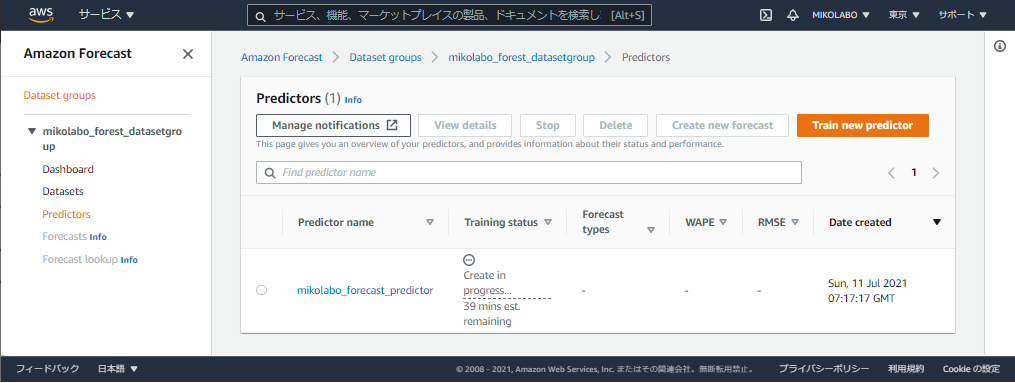
あと39分かかりそう!!
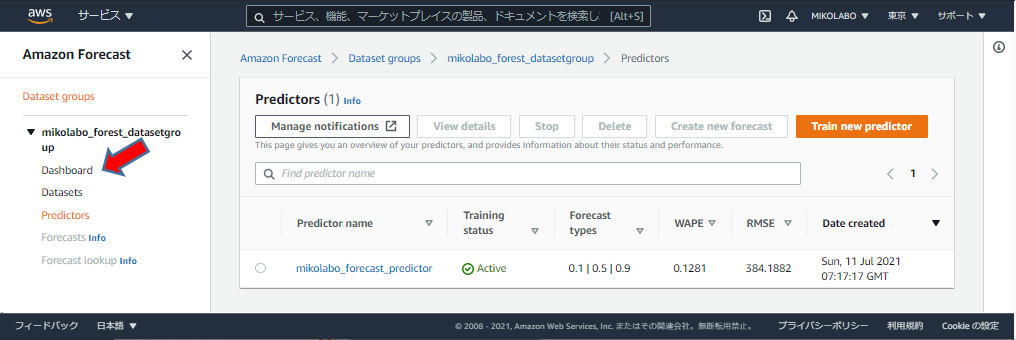
Training Status = Active になったので、
「Dashboard」をクリック
4. 予測を⾏う
予測の作成画⾯へ移動 Predictor の学習が終わると予測を作成できる
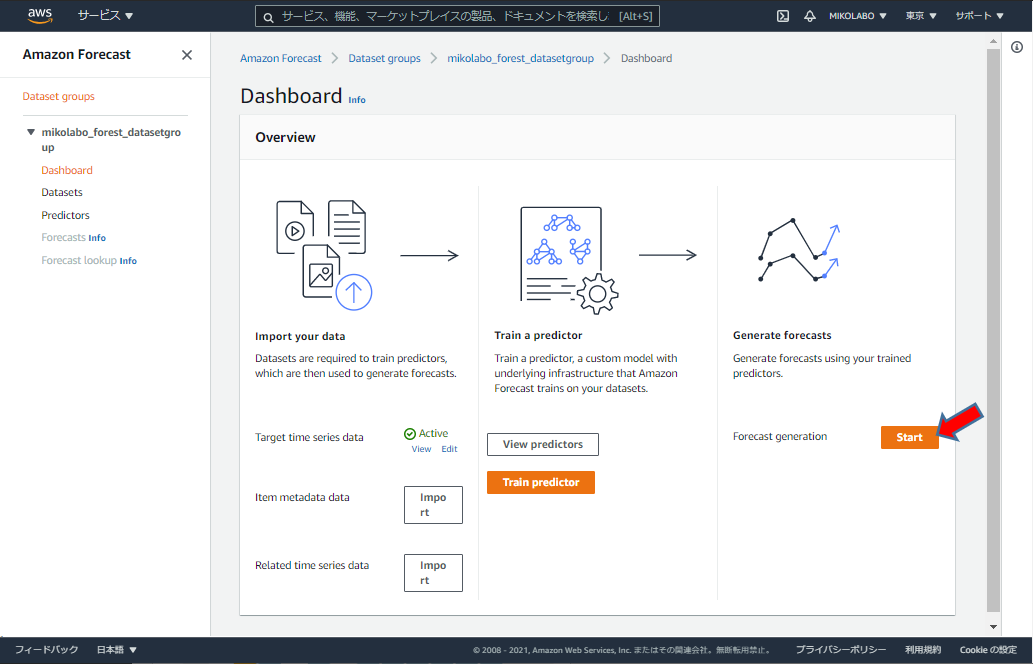
「Start」をクリック
予測の作成
学習した Predictor から予測 (forecast) を作成する
予測を作成した段階では予測値を確認できず、
Forecast export (S3へ出力)、Forecast lookup (条件を指定して予測値を出力) する必要がある

Forecast の作成が完了すると Lookup forecast を実行できる
「Lookup forecast」をクリック
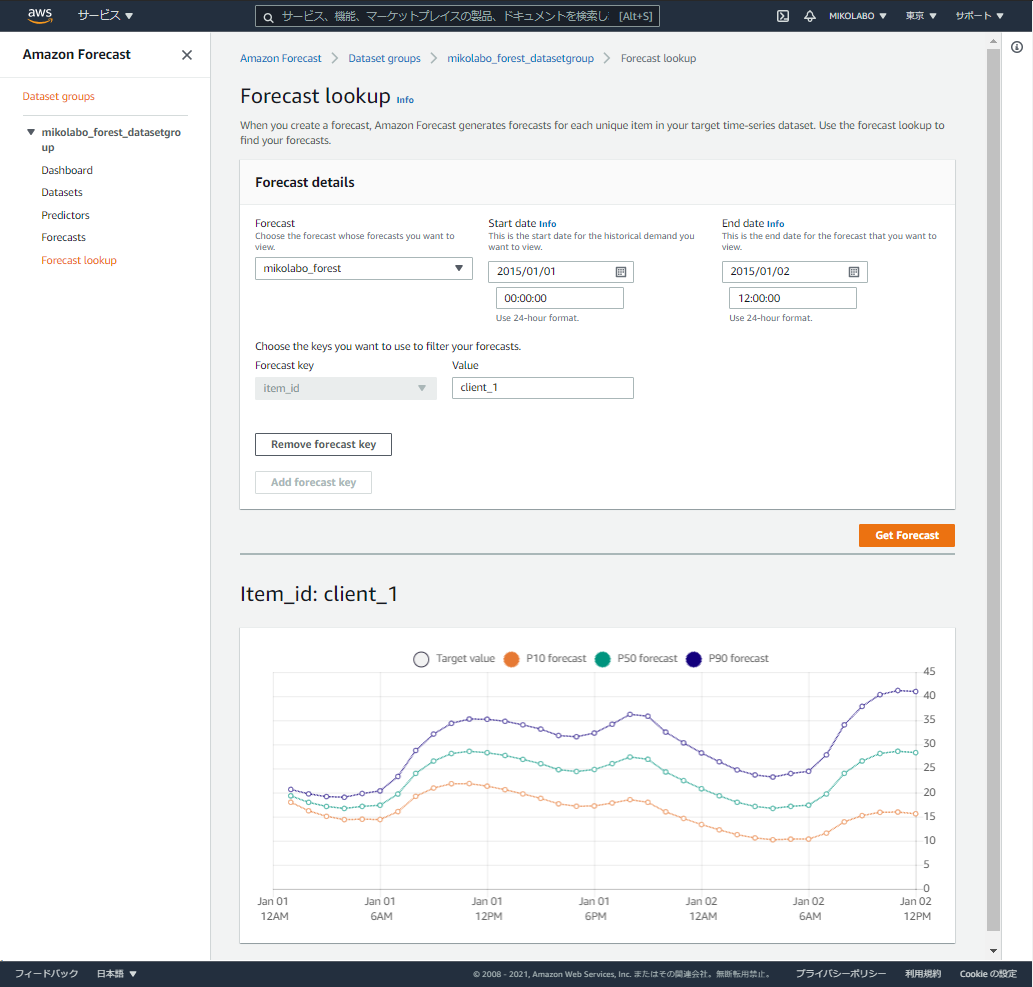
作成したForecast を選択:mikolabo_forest
Start: 2015/01/01 0時0分
(インポートしたデータ2014/12/31 23時 の次)
End: Start + Forecast horizon
(forecast horizon が36 のとき2015/01/02 12時 (36時間後)
Value = csv の ITEM_ID の値を入力 :client_1
結果が下に表示される
50が示す値は、50%の確率でこの値以下に収まることを表す
P10とP90はどこまで小さい・大きい値をとりうるかを示す
需要予測で欠品を防ぎたい場合は、P90にあわせて多めに
在庫を補充
Forecast export (S3に⼀括出⼒) Forecast を選んで Create forecast export
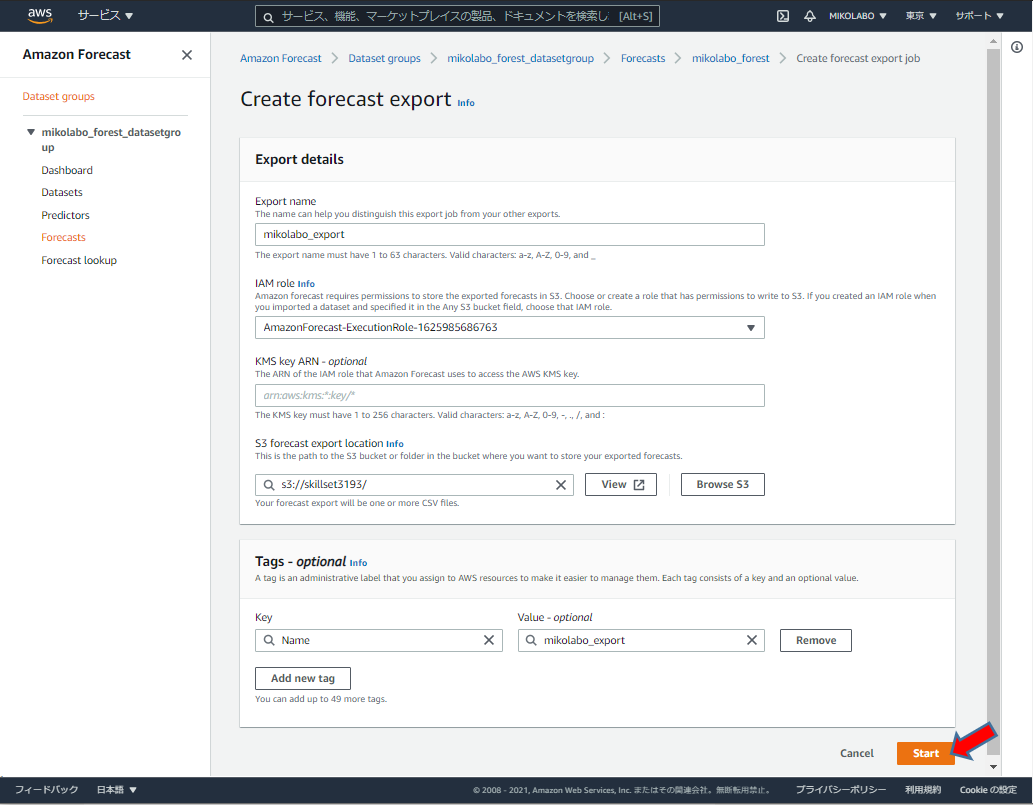
任意の名前を入れる
S3の保存先を指定
タグも一応設定した
「Start」をクリック
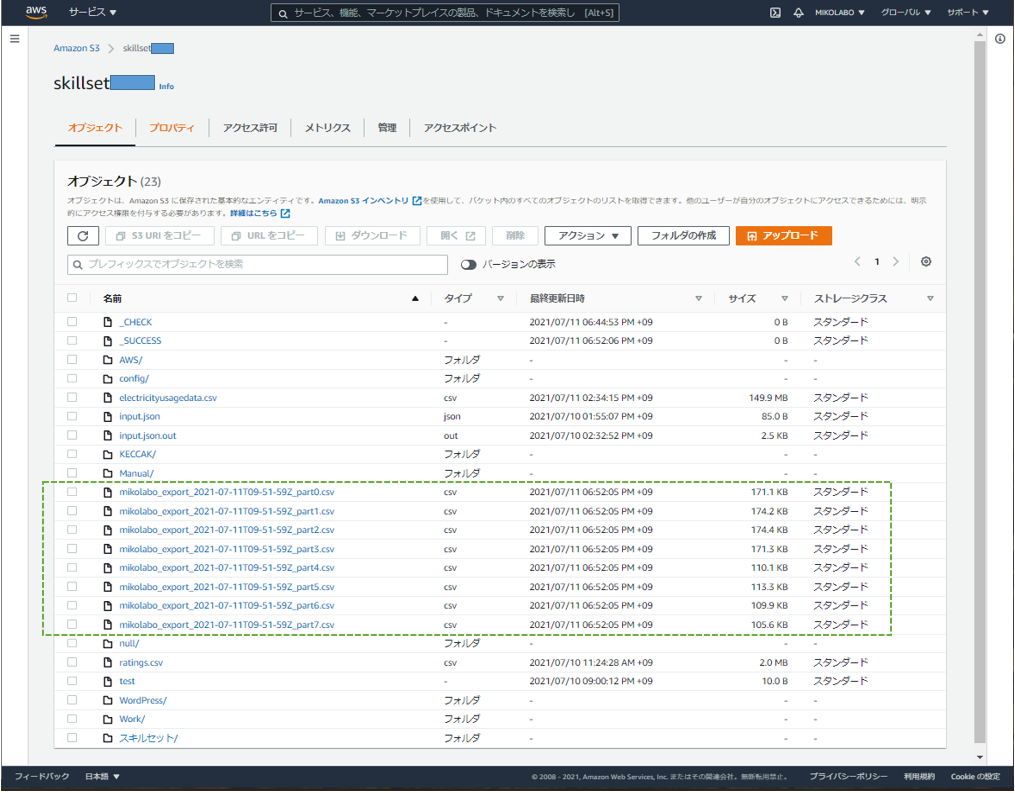
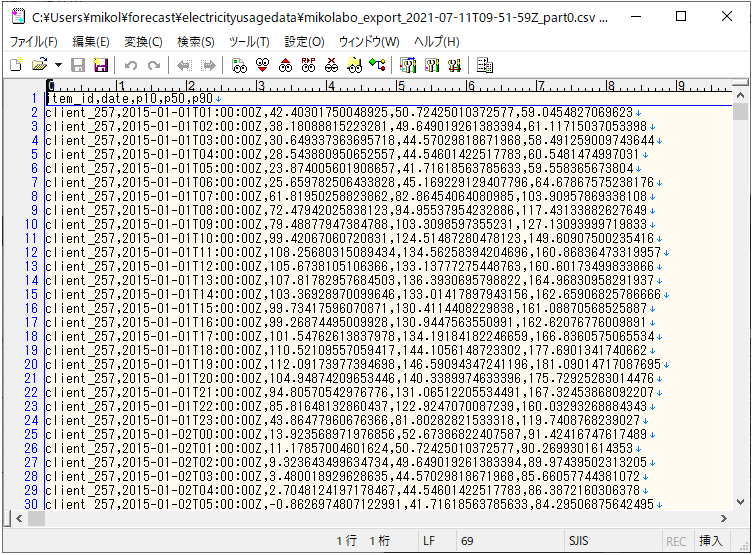
エクスポートした
「mikolabo_export_2021-07-11T09-51-59Z_part0.csv」
5.リソースを削除する
リソースの削除: S3
- 今回利用したデータセット (csv)
- 完全な予測のエクスポートを実施した場合は、その出力ファイル
リソースの削除: Amazon Forecast
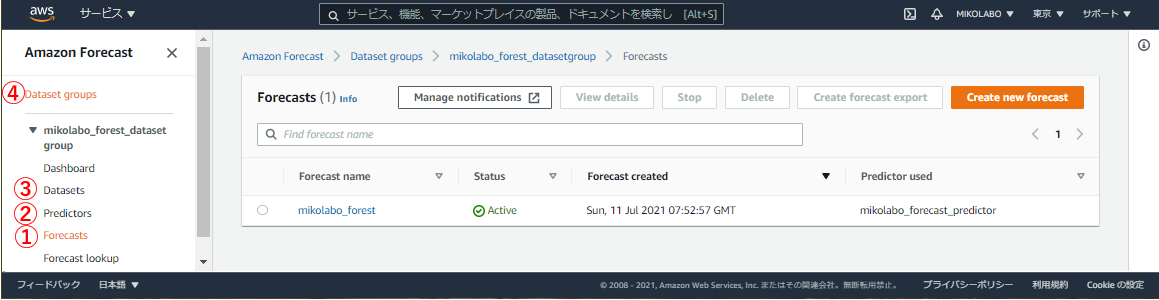
- 左のメニューから、①Forecasts, ②Predictors, ③Datasets 各ページで順に選び、各ページでDelete を実⾏する
- すべて削除した後、左のメニューから Dataset groups を選んで、④Dataset groupも削除