
AWS Lambda + AI = 音声文字起こしと感情分析 (その5:Polly)
AWSのホームページの初心者ハンズオンにある「AWS Lambda と AWS AI Services を組み合わせて作る音声文字起こし & 感情分析パイプライン 」の内容を自分のAWSアカウントでやってみました。
前回投稿の S3+Lambda+Transcribe+Comprehend をパイプラインを実装した続きで、5パート目です。
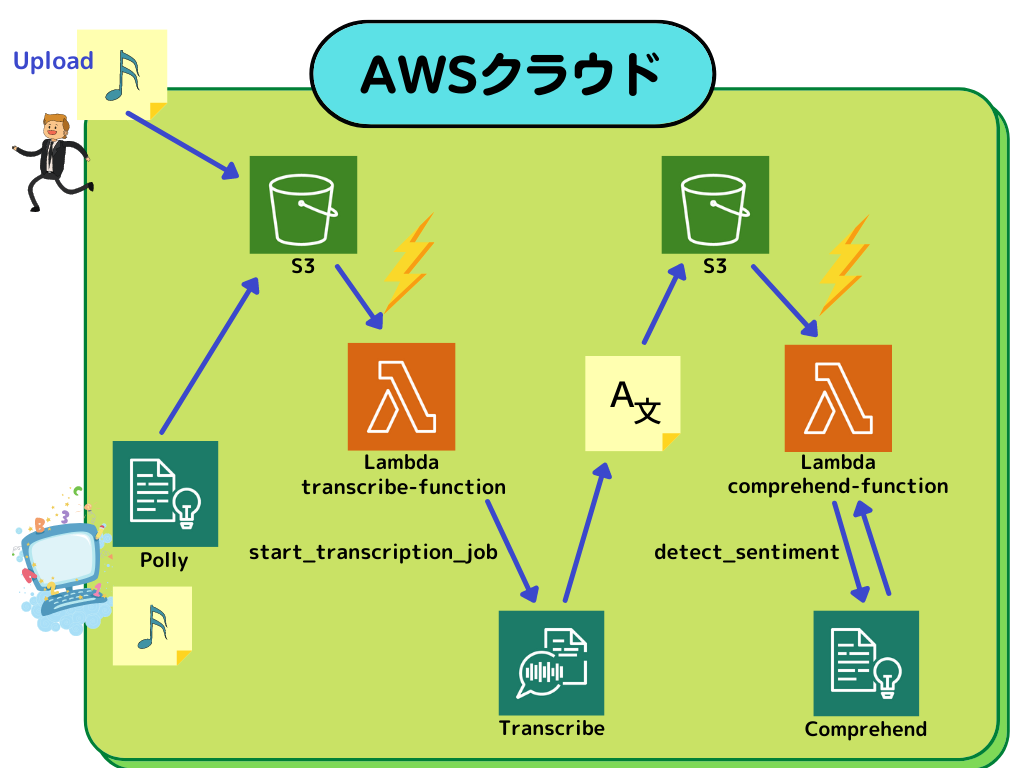
ざっくりと基本構成を図で表してみて、4パート目にPollyを追加した構成です。
ちなみに、 Amazon Polly については、以前の投稿に
があります。
Amazon Polly で読み上げてみる
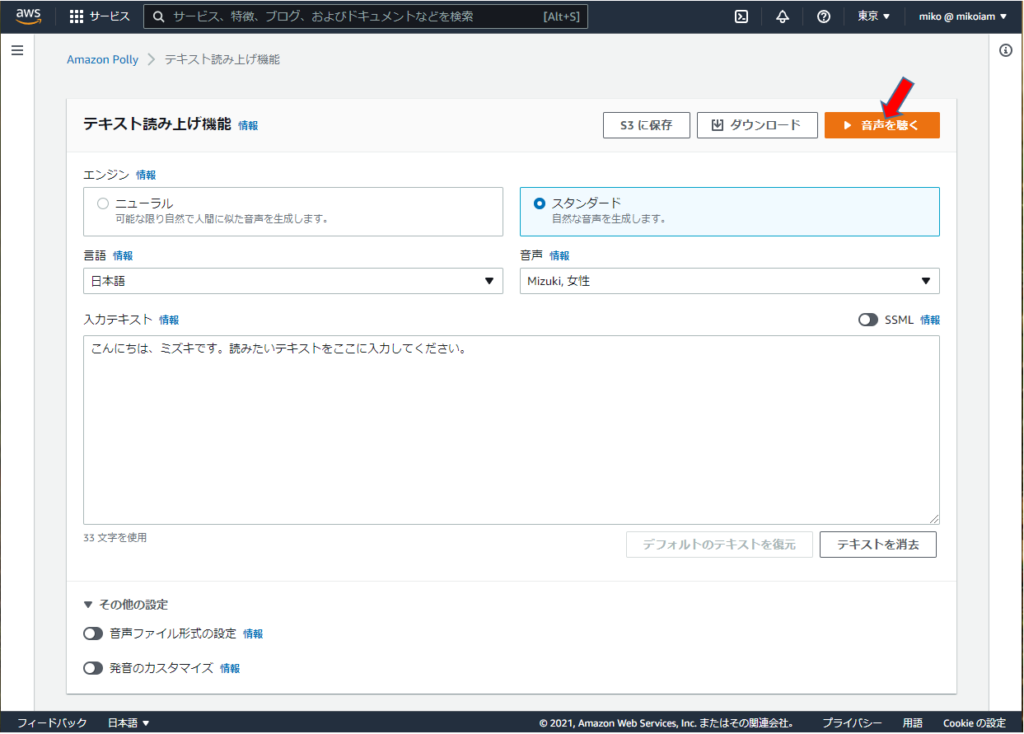
女性声(Mizuki)で、入力テキストにある
「こんにちは、ミズキです。読みたいテキストをここに入力してください。」
が読み上げられる。
SSML 拡張ドキュメントの合成
https://docs.aws.amazon.com/ja_jp/polly/latest/dg/ssml-synthesize-speech-cli.html
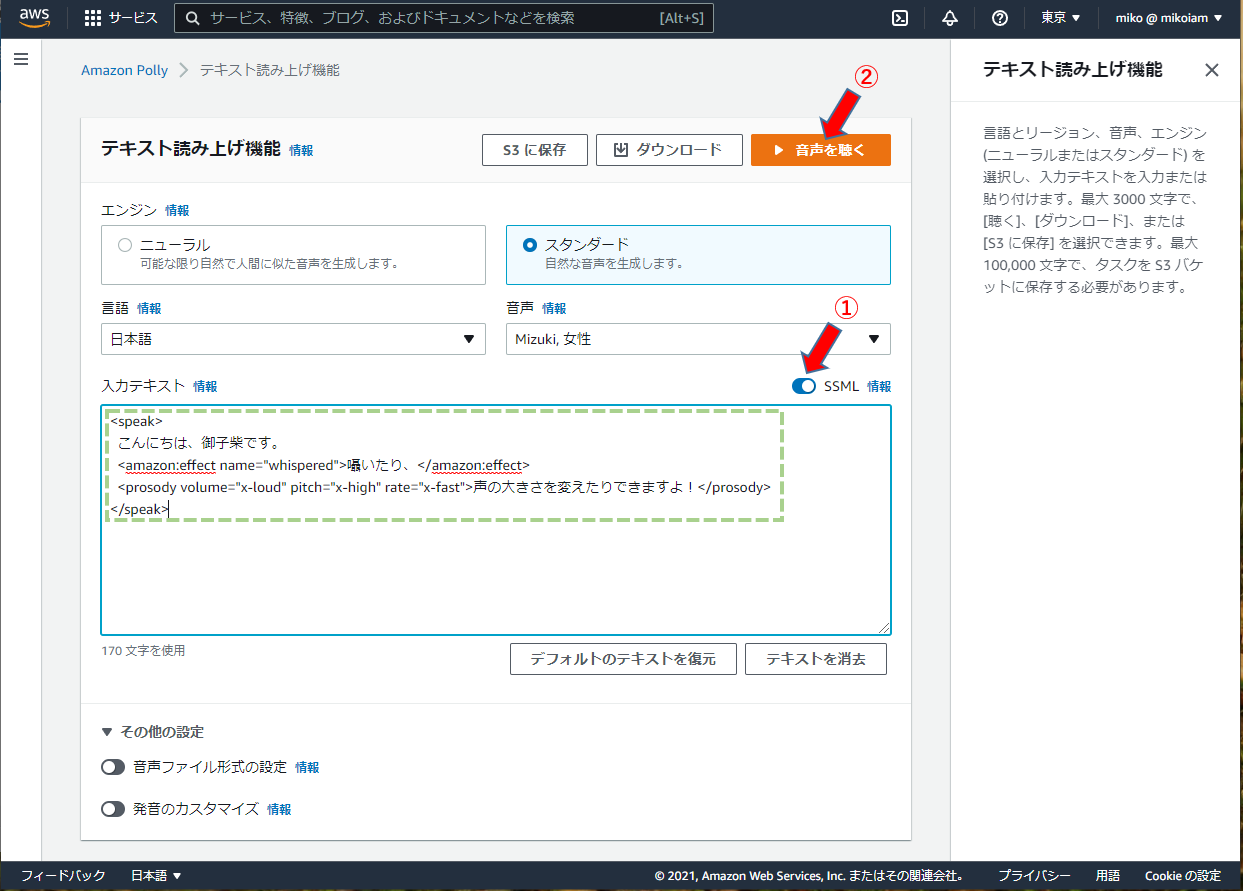
<speak>
こんにちは、御子柴です。
<amazon:effect name="whispered">囁いたり、</amazon:effect>
<prosody volume="x-loud" pitch="x-high" rate="x-fast">声の大きさを変えたりできますよ!</prosody>
</speak>
一般的な Amazon Polly タスクで SSML を使用する
一時停止の追加
単語間に一時停止を追加するには、 要素を使用します。次の SSML synthesize-speech コマンドは、 要素を使用して、「Hello」と「World」の間に 300 ミリ秒のディレイを追加します。
<speak>
Hello <break time="300ms"/> World.
</speak>音量、ピッチ、速度の制御
ピッチ、話す速度、話す音量を制御するには、 要素を使用します。
次の synthesize-speech は 要素を使用して音量を制御します。
<speak>
<prosody volume="+20dB">Hello world</prosody>
</speak>
次の synthesize-speech コマンドは 要素を使用してピッチを制御します。
<speak>
<prosody pitch="x-high">Hello world.</prosody>
</speak>次の synthesize-speech コマンドは 要素を使用して話す速度を指定します。
<speak>
<prosody rate="x-fast">Hello world.</prosody>
</speak>次の例に示すように、 要素に複数の属性を指定できます。
<speak>
<prosody volume="x-loud" pitch="x-high" rate="x-fast">Hello world.</prosody>
</speak>Whispering
単語をささやくには、<amazon:effect name="whispered"> 要素を使用します。次の例で、 <amazon:effect name="whispered">要素は Amazon Polly に「little lamb」をウィスパーするようにに指示します。
<speak>
Mary has a <amazon:effect name="whispered">little lamb.</amazon:effect>
</speak>
この効果を高めるには、<prosody> 要素を使用して、ウィスパー音声をわずかに遅くします。
単語を強調する
単語または語句を強調するには、<emphasis> 要素を使用します。
<speak>
<emphasis level="strong">Hello</emphasis> world how are you?
</speak>
特定の単語の発声方法を指定する
読み上げられるテキストの種類に関する情報を提供するには、<say-as> 要素を使用します。 たとえば、次の SSML <say-as> は、テキスト 4/6 を日付として解釈する必要があることを示します。属性 interpret-as="date" format="dm" は、月/日の形式の日付として発声する必要があることを示します。 また、<say-as> 要素は、に数字を分数、電話番号、測定単位などとして発声するようAmazon Polly に指示するために使用することもできます。
<speak>
Today is <say-as interpret-as="date" format="md" >4/6</say-as>
</speak>
生成される音声は「Today is June 4th」となります。<say-as> タグは、interpret-as 属性で追加コンテキストを指定することで、そのテキストをどのように解釈するかを説明します。 合成された音声を確認するには、生成された speech.mp3 ファイルを再生します。 この要素の詳細については、「特殊なタイプの単語の発声方法を制御する 」 (https://docs.aws.amazon.com/ja_jp/polly/latest/dg/supportedtags.html#say-as-tag)を参照してください。
外国語の発音の向上
Amazon Polly では、入力テキストは選択されたボイスと同じ言語であることを前提としています。 入力テキスト内の外国語の発音を向上させるには、synthesize-speech 呼び出しで、xml:lang 属性を使用して対象言語を指定します。これにより、Amazon Polly はタグ付けされた外国語に対し異なる発音ルールを適用します。 次の例では、入力テキストの言語のさまざまな組み合わせを使用して、外国語の音声と発を指定する方法を説明します。 使用可能な言語の完全なリストについては、「Amazon Polly でサポートされる言語(https://docs.aws.amazon.com/ja_jp/polly/latest/dg/SupportedLanguage.html)」を参照してください。 次の例では、音声 (Joanna) は米国英語の音声です。デフォルトでは、Amazon Polly では、入力テキストは選択されたボイスと同じ言語 (この場合は米国英語) であることを前提としています。 使用すると、xml:langタグを使用すると、Amazon Polly はテキストをスペイン語として解釈し、テキストは外国語の発音ルールに基づいて選択した音声がスペイン語を発音する場合のように発音されます。このタグがない場合、テキストは選択された音声の発音ルールを使用して発声されます。
<speak>
That restaurant is terrific. <lang xml:lang="es-ES">Mucho gusto.</lang>
</speak>
入力テキストの言語は英語のため、Amazon Polly は生成されたスペイン語音素をもっとも近い英語音素にマッピングします。 その結果、Joanna は、スペイン語を正しく発音しているが米国英語のアクセントがある米国英語のネイティブスピーカーとして発声します。 注記 より似通っている言語同士の組み合わせであれば、他の組み合わせよりうまく機能します。
音声ファイルを作成して、S3バケットに保存する → Transcribe → Comprehend の流れで処理する
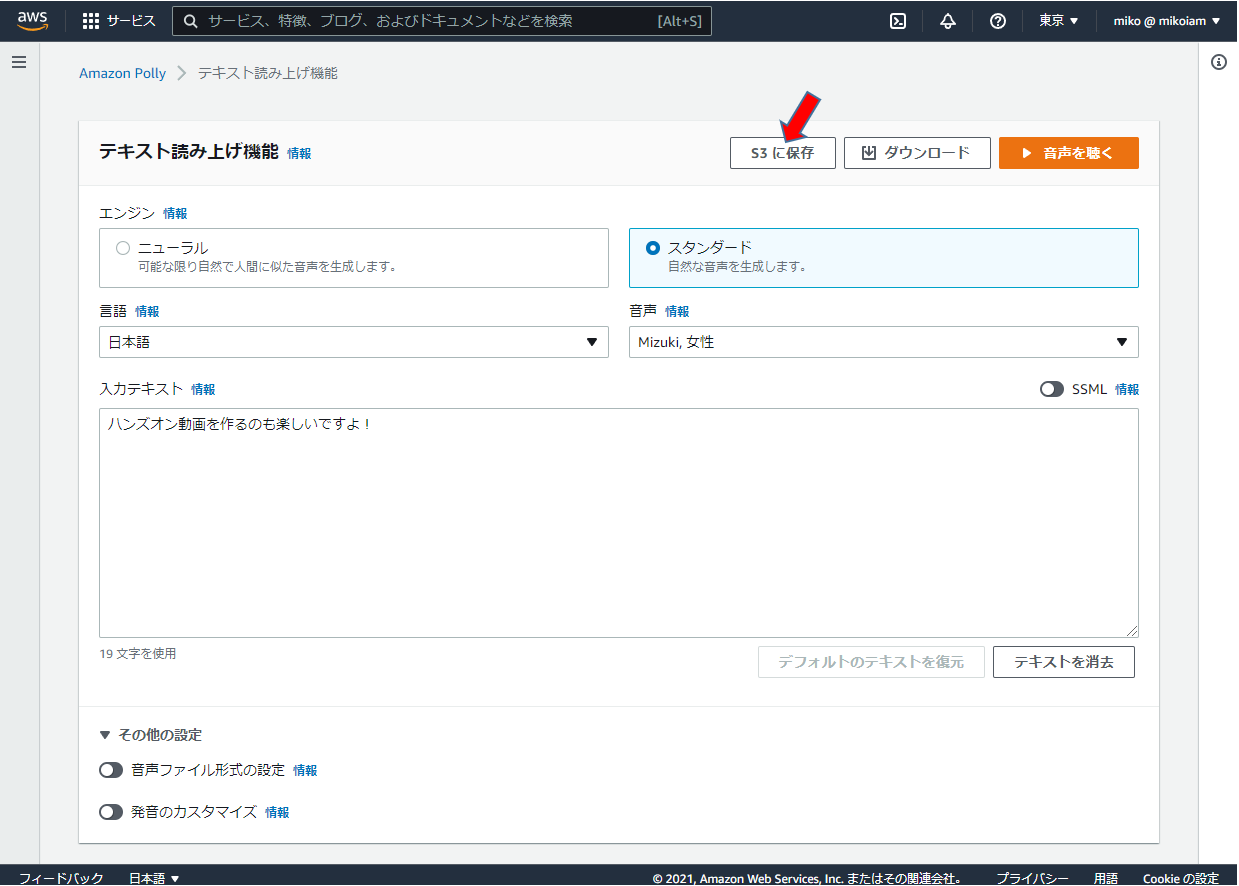
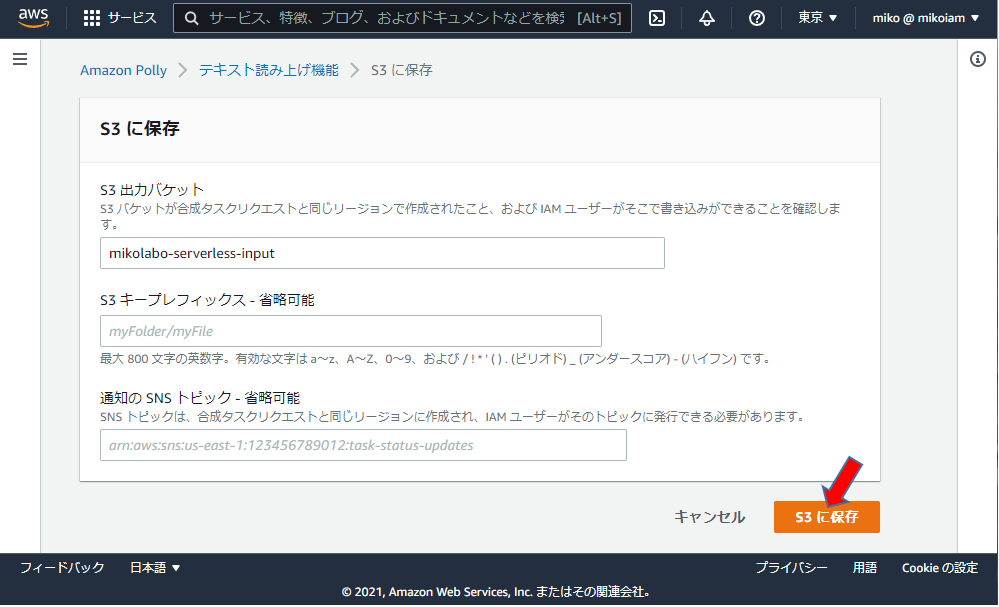
S3出力バケットに
「mikolabo-serverless-input」
を指定
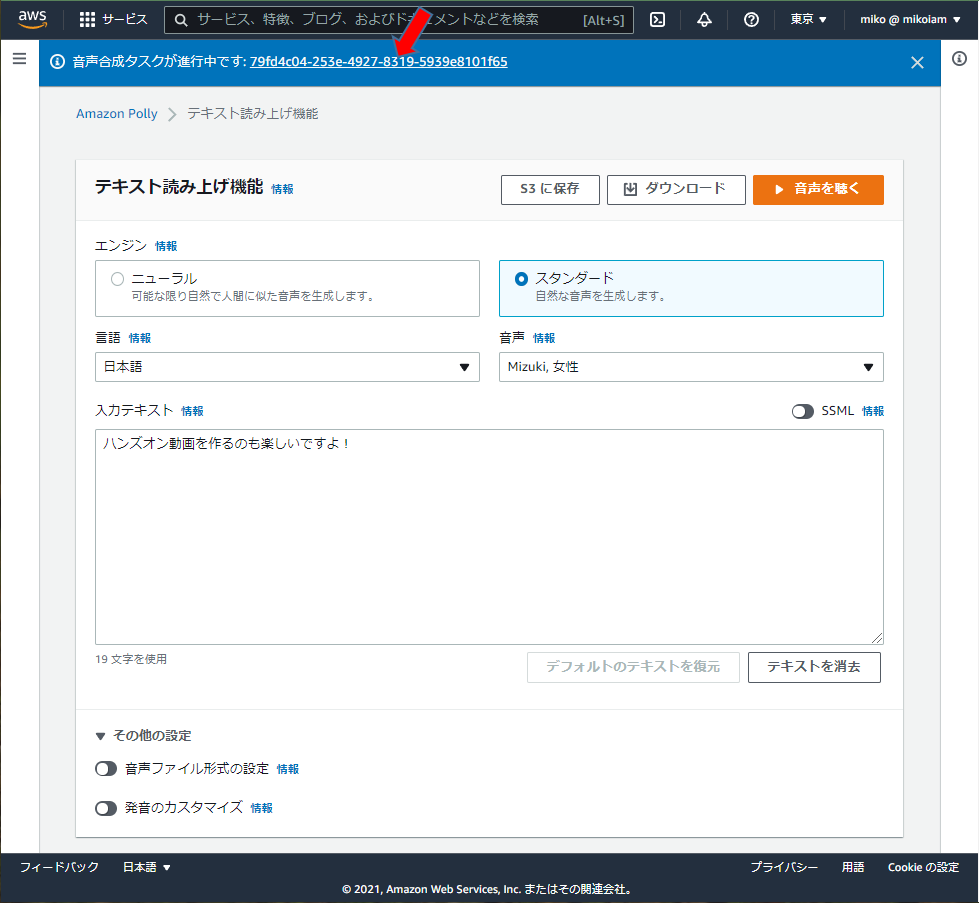
画面上部の音声合成タスク
のリンクをクリック
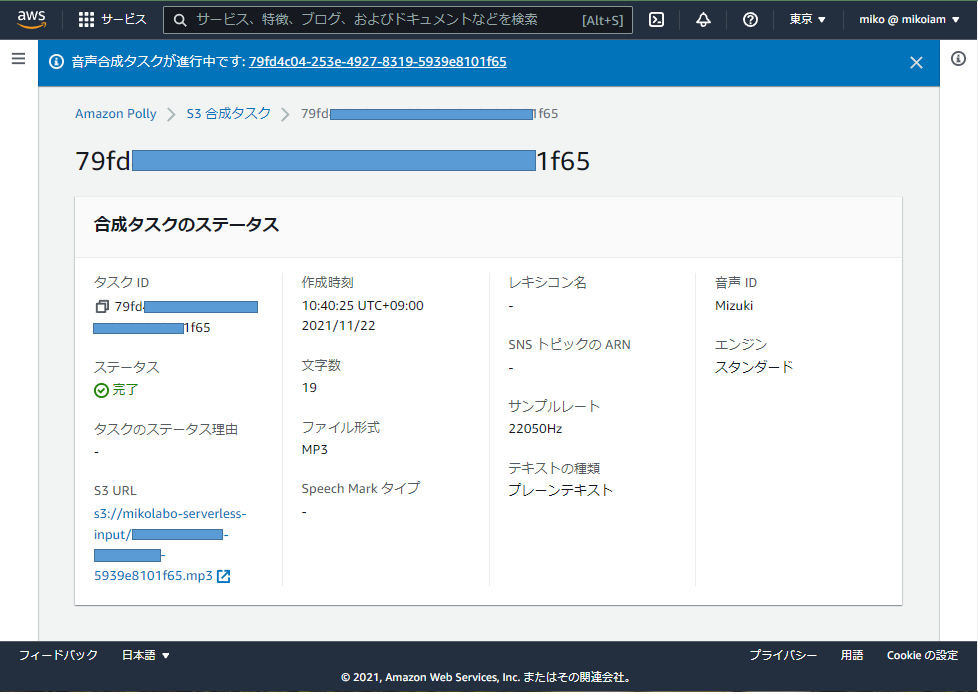
S3バケットに保存された
Lambda関数「comprehend-function」から結果を確認
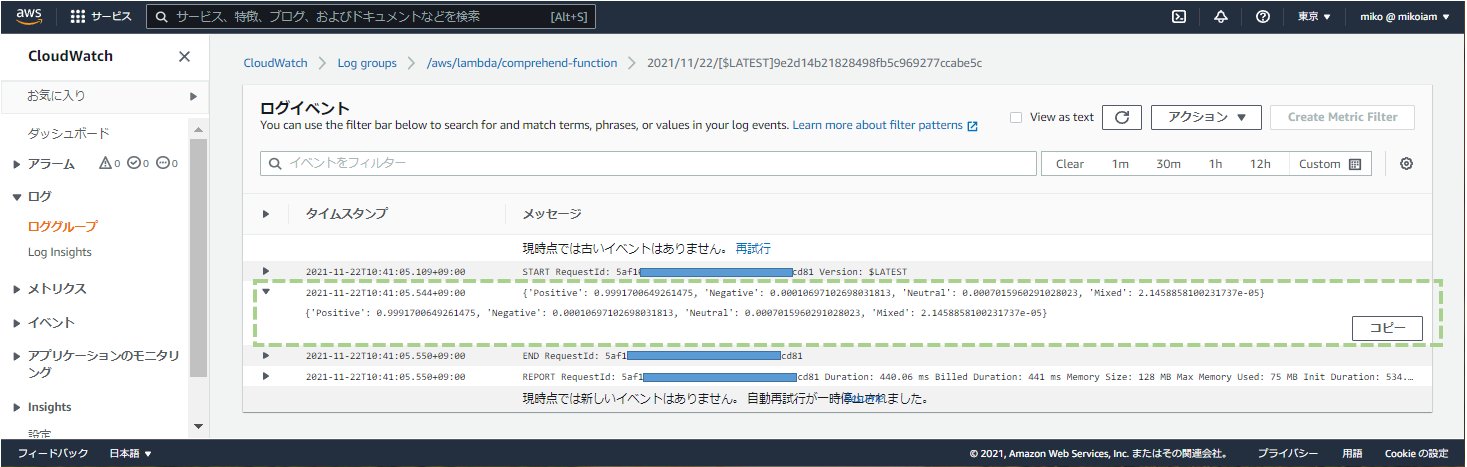
今、保存した音声ファイルの感情の分析値が表示されている。
‘Positive’: 0.9991700649261475,
‘Negative’: 0.00010697102698031813,
‘Neutral’: 0.0007015960291028023,
‘Mixed’: 2.1458858100231737e-05
以上。その1~5までの投稿で、以下の機能を組み込みました。
- S3トリガーで Lambdaファンクションを起動する
- Amazon Transcribeを使って文字起こしを試してみる
- S3への音声ファイルアップロードをトリガに Lambdaを起動し、Transcribeするパイプラインを作る
- パイプラインで文字起こししたテキストを Comprehend で感情分析する
- Amazon Polly で作成した音声ファイルをパイプラインに投入する(今回の投稿)
ちなみに、ハンズオンでは上記機能の確認を行った後始末に、以下の順番でリソースを削除します。
- S3バケットの削除 インプット用S3バケット、アウトプット用S3バケット
- Lambda関数の削除 Transcribe用Lambda関数、Comprehend用Lambda関数
- LAMロールの削除 Transcribe用IAMロール、Comprehend用IAMロール
